
Understanding and Optimizing Packed Neural Network Training for Hyper-Parameter Tuning
Subject
This paper studies jointly training multiple neural network models on a single GPU. Our research prototype is in TensorFlow, and we evaluate performance across different models (ResNet, MobileNet, DenseNet, and MLP) and training scenarios.
Contribution
- packing two models can bring up to 40% performance improvement over unpacked setups for a single training step and the improvement increases when packing more models;
- the benefit of a pack primitive largely depends on a number of factors including memory capacity, chip architecture, neural network structure, and batch size;
- there exists a trade-off between packing and unpacking when training multiple neural network models on limited resources; (4) a pack-based Hyperband is up to 2.7× faster than the original Hyperband training method in our experiment setting, with this improvement growing as memory size increases and subsequently the density of models packed.
Introduction
Background
- It is increasingly the case that a diverse set of model training tasks share limited training resources. The long-running nature of these tasks and the large variation in their size and complexity makes efficient resource sharing a crucial concern.
- These concerns are compounded by an extensive trial-and-error development process where parameters are tuned and architectures are tweaked that result in a large number of trial models to train.
Multi-tenant training
granularity of full devices
Such a policy can result in poor resource utilization due to its coarse granularity. If a training workload consists of a large number of small neural networks, allocating entire devices to these training tasks is wasteful and significantly delays any large model training.
fine-grained resource sharing
Unlike CPUs, the full virtualization of GPU resources is very nascent. In this setting, those parallel kernels would transfer and store multiple copies of the same training data on the device.
Pack models
A multiple static neural network architectures (e.g., ones that are typically used in Computer Vision) can be rewritten as a single concatenated network that preserves the input, output, and backpropagation semantics.
- facilitate partitioning of a single device
- synchronize data processing threads on GPUs
- collapse common variables in the computation graph.
It is often the case during hyperparameter or neural architecture search that multiple similar networks are trained, and packed configurations can feed a single I/O stream of training examples to each variant of the network. In contrast, an isolated sharing configuration may lead to duplicated work and wasted resources.
Conclusion
- packing models together is not strictly beneficial, that packing models that are too different can result in excessive blocking and wasted work.
- this paper studies the range of possible improvements (and/or overheads) for using packed configurations.
- design an algorithm that heuristically finds performant packing configurations
Background
Motivation
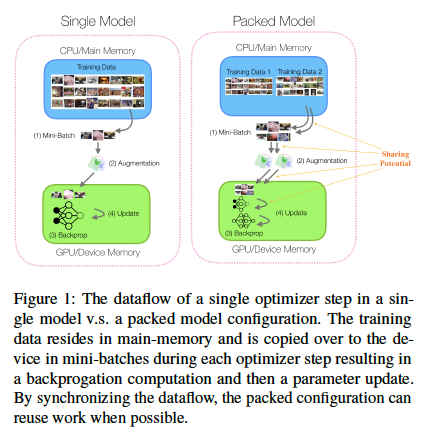
Suppose, we are training two models on the same dataset to test if a small tweak in network architecture will improve performance. If the system could pack together models when compatible in size, then these redundant data streams can be fused together to improve performance.
Basic Framework API
We desire a framework that can pack models together when possible and jointly optimize their respective computation graphs to reduce redundant work.
Each training task is identified by four inputs.
- Model.
- Optimizer.
- Batch Size.
- Steps.
Such a system requires three basic primitives load, pack, and free.
- load
1
load(model, device)
- free
1
checkpt = free(model, device)
- pack
1
2
3
4output1 = nn1(input1)
output2 = nn2(input2)
==>
[output1 output2] = nn12([input1, input2])
This pack operation is fully differentiable and preserves the correctness semantics of the two original networks. The models can be jointly trained.
If the models are too different the device may waste effort stalling on one model.
Implementation
Basic Packing
1 | resnet_out = ... #reference to resnet output |
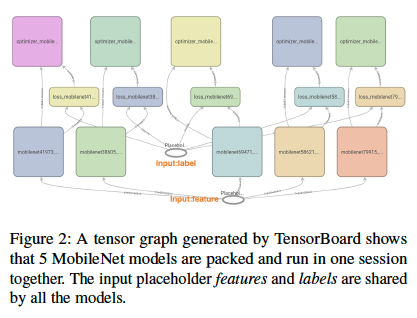
If one of the models is significantly more complex than the others, it will block progress.
- Misaligned Batch Sizes
Our method is to rewrite the packed model to include a dummy operation that pads models with the smaller batch size to match the larger ones in dimension.

- Misaligned Step Counts
when the earliest model finishes, the packed model has to be check-pointed and reconfigured to only include the remaining models. This introduces a switching overhead of loading and freeing the device memory.
Eliminating Redundancy
Dimensional differences between the models or training differences between the models can lead to wasted work.
In this case, input1 and input2 refer to the same dataset. We can avoid transferring the batch multiple times by symbolically rewriting the network description to refer to the same input:
1 | output1 = nn_relu(input1) |
When packing models that use the same preprocessing tasks, the pack primitive fuse the steam processing accordingly.
Profiling Model Packing
As it stands, model packing leads to the following tradeoffs. Potential performance improvements include:
- performing computations (inference and backpropagation) in parallel if and when possible,
- eliminating redundant data transfers when models are trained on the same dataset,
- combining redudant computations including preprocessing.
On the other hand, the potential overheads include:
- models that dominate the device resources and block the progress of the others,
- padding misaligned batch sizes,
- loading and unloading models with a differing number of training steps.
In particular, we find that packing is most beneficial when the models jointly trained are similar and train on the same dataset.
Metrics
we define the improvement metric as follows:
[IMPV]
1 | Ts(Seq) = Ts(Model 1)+···+Ts(Model n) |
The switching overhead of training n models is defined as:
[SwOH]
1 | SwOH = Te(Seq)−Te(Model 1)···−Te(Model n) |
Micro-Benchmarks
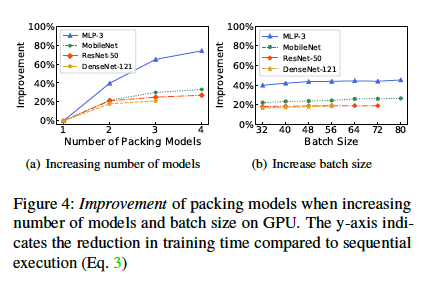
Improvement of packing models when increasing number of models and batch size on GPU.
Ablation Study
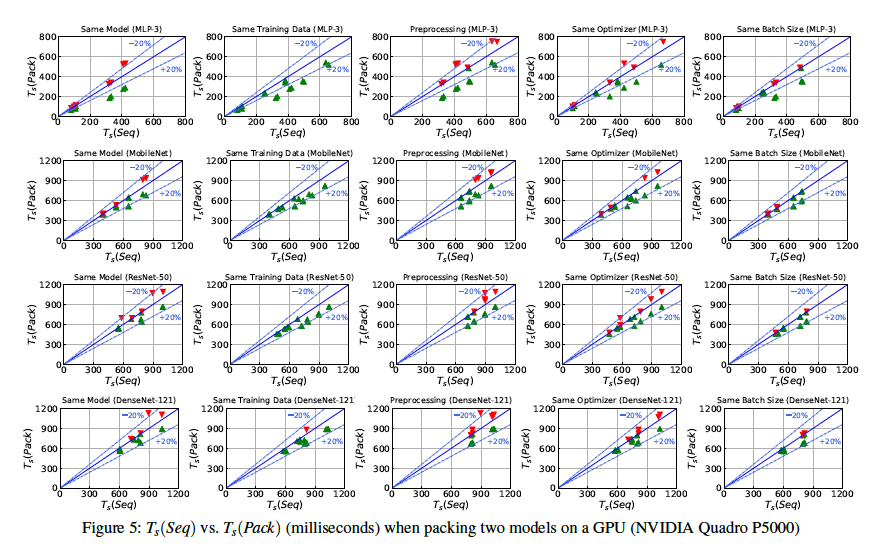
We test more cases based on the five factors:
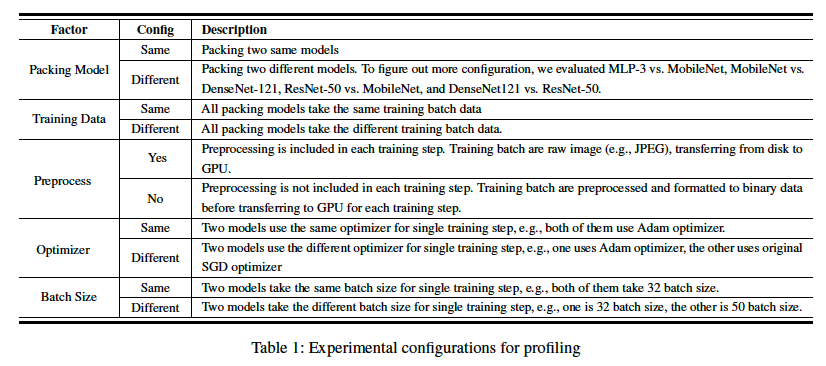
The best scenarios are where the same training data and same batch size are used. Over all the configurations, the pack primitive always brings benefits when we training models with same data or same batch size since it will reduces the data transfer.
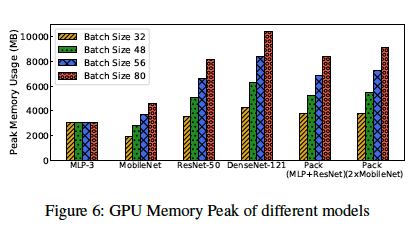
Memory Usage
MLP-3 model maintains the same as batch size goes up. For convolutional neural networks like ResNet, MobileNet and DenseNet, the GPU memory usage is proportional to the batch size.
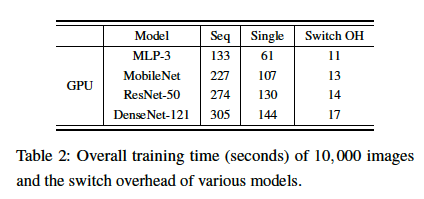
Switching Overheads
The switching overhead is minor compared to the overall training time.
Packing vs CUDA Parallelism
Although CUDA supports it, our results show that it is an inefficient technique. We find that in all but the simplest cases lead to an out-of-memory error: “failed to allocateXXXfromdevice:CUDA_ERROR_OUT_OF_MEMORY: out of memory”.
Packing-Aware Hyperparameter Search
Hyperband for Hyperparameter Search
Hyperband works by repeatedly sampling random parameter configurations, partially training models with those configurations and discarding those configurations that do not seem promising.
Hyperband is very effective for parallel hyperparameter search in comparison to sequential algorithms such as Bayesian Optimization.
The algorithm is long-running since it consists of a large number of trial models/configurations to run and each of them will occupy the entire GPU resource when running.
Packed Hyperband
Our pack primitive allows Hyperband to jointly train configurations when possible thereby reducing the overall training time.
The optimization problem is to search over all packable partitions to find the best possible configuratio. We call this primitive pack_opt(), which solves the search problem to produce feasible packing configuration.
Heuristic Solution
We design a nearest-neighbor based heuristic. The method randomly selects a single configuration as the centroid and packs all other configurations similar to it until the device runs out of memory.
For calculating the similarity, we map hyperparameter configurations to multidimensional feature space and measure the pairwise Euclid distance among all the configurations.
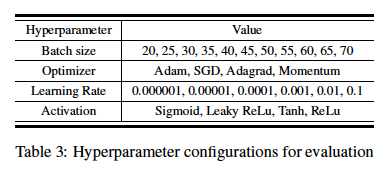
We take standard distance unit as 1, and compute the distance between any two configurations. For categorical hyperparameters like optimizer and activation, the distance is 0 if same and 1 if different, for numeric hyperparameters, we use the index to compute distance.
Evaluation
A Random Pack Hyperband can save more time than Batch-size Pack Hyperband since it achieves a better GPU resource utilization. Our kNN strategy gets the best of both worlds: it finds the most beneficial packing opportunities while completely utilizing the available resources, and benefits are scalable when deployed in an environment with larger GPU resource.
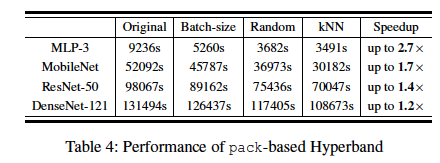
Related Work
We focus on related work that studies placement in machine learning and hyperparameter tuning systems.
Systems for Hyperparameter Tuning
- Google Vizier [3] exposes hyperparamter search as a service to its organization’s data scientists. Aggressive “scale-out” has been the main design principle of Vizier and similar systems.
- A more controlled resource usage. CHOPT proposes a novel stop-and-go scheme that can take advantage of transient cloud based resources.
- HyperSched, proposes a scheduling framework for hyperparameter tuning tasks when there are contended specialized resources. And, some work has been done on resource management [33] and pipeline re-use [18] in the non-deep learning setting.
Coarse-grained Multi-tenancy
dividing resources at the granularity of full devices
- One of the earliest works in this space was the TetriSched project, which considered how to specify and optimize locality constraints during process scheduling.
- Project Philly analyzed a trace of machine learning workloads run on a large cluster of GPUs in Microsoft and indicated the trade-off between locality and GPU utilization.
Fine-grained Multi-tenancy
There are a number of projects which attempt to achieve the fine granularity. This idea called packing.
- Gandiva is a cluster scheduling framework for deep learning jobs that provides primitives such as time-slicing and migration to schedule different jobs, it supports packing as well, implementing packing arrangements using a greedy algorithm without decent optimizations.
- Narayanan et al. [26] discuss a packing idea that tries to combine various models and trains them together.
However, this proposed packing method of layer fusion has limited application scenarios as it only focuses on models with the same batch size.
Multi-tenancy Systems
- CROSSBOW
- PipeDream
- Ease.ml
Discussion and Limitations
Any distributed training and the regarding optimization is out of the scope of the paper.