Using Spatio-Temporal Information in API Calls with Machine Learning Algorithms for Malware Detection(2009)
This paper uses statistical features which are extracted from both spatial (arguments) and temporal (sequences) information available in Windows API calls.
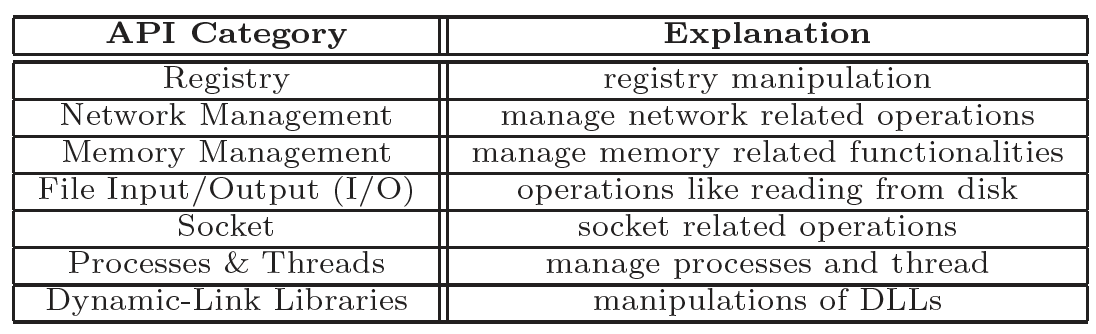
The Windows API provides thousands of distinct API calls serving diverse functionalities. However, this paper chooses short-listed 237 API calls which are widely used by both benign Windows applications and malware programs. They refer to the short-listed calls as the core-functionality API calls. They further divide the core-functionality API calls into seven different categories: (1) registry, (2) network management, (3) memory management, (4) file I/O, (5) socket, (6) processor and threads, and (7) dynamically linked libraries (DLLs).
spatial information
The spatial information refers to the set of arguments which always are generally address pointers or variables that hold crisp numerical values. They use fundamental statistical and information theoretic measures to quantify the spatial information. These measures include mean, variance, entropy, minimum, and maximum of given values. For example, they have observed that malware writers suffice on lean and mean implementations of malware programs with low memory usage so that they can remain unnoticed for as long as possible.
Temporal information
Temporal information refers to represents the order of invoked API calls where call sequences and control flow graphs are the most popular techniques. By some auto-correlation analysis, this paper finds that 3rd order dependence has a high correlation for both benign and malware programs, so it finally uses 3-gram API call sequence. Then they model API call sequence using a discrete time Markov chain. The order of a Markov chain represents the extent to which past states determine the present state. They uses 3rd order Markov chain to represent the probability of transitions, which means the next possible API call depends on previous three API calls. The transition matrix T looks like:

Each element in this matrix indicates the probability of a new API call when they have observed the first 3 API calls. Then the paper information gain to select the most discriminative features:
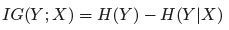
Specifically, for each element in the matrix, the paper uses a to count its appearance times in benign training samples and b to count in malware samples. Then this element’s information gain can be computed by:
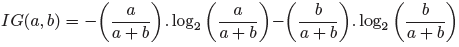
Experiment
The paper designs an experiment using spatio-temporal features’ set over standalone spatial or temporal features set.
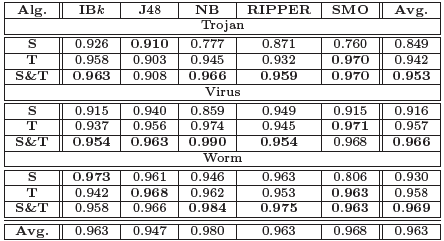
The table shows that that spatial and temporal features alone can provide on the average detection accuracies of approximately 0.898 and 0.952 respectively. However, the combined spatio-temporal features’ set provide an average detection accuracy of 0.963 – approximately 5% improvement over standalone features’ set.
NB with spatio-temporal features’ set provides the best detection accuracy of 0.980. It is closely followed by SMO which provides the detection accuracy of 0.968. On the other hand, J48 provides the lowest accuracy of 0.947.
Discovering Similar Malware Samples Using API Call Topics(2015)
This paper aims to extract similar malware samples automatically using the concept of “API call topics,” which represents a set of API calls that are intrinsic to a specific group of malware samples. They present an unsupervised approach to extract API call topics from a large corpus of API calls. Through analysis of the API call logs collected from thousands of malware samples, they demonstrate that the extracted API call topics can detect similar malware samples. The proposed approach is expected to be useful for automating the process of analyzing a huge volume of logs collected from dynamic malware analysis systems.
The key idea of this paper is that they present an unsupervised approach to extract API call topics which can detect similar malware samples.
Dataset
The data of this paper consists of Cuckoo Sandbox logs of 2,641 malware samples collected from September 2012 to March 2013. The format of all malware samples was the Portable Executable (PE) format used in Windows operating systems. These malware samples were executed on Cuckoo Sandbox in 90 seconds and generated 1.7 GB of dynamic analysis logs in JSON format.
Some interesting they found:
- The majority of the samples had more than 400 API calls, a few samples had only a small number of API calls.
- Malware samples that exhibited a very low number of API calls likely failed to execute correctly because of the anti-VM techniques. Therefore, they pruned malware samples with fewer than 10 API calls.
Methodologies
API words features
This paper parsed the JSON formatted Cuckoo Sandbox log, then they used three variables(API function names, arguments names, argument values) to convert an API call into an “API word”, and they omitted return values and thread IDs.
They used level-3 approach to compress the API logs. Its definition is api:n1:v1:n2:v2:…, for example, “LdrGetDllHandle”:”FileName”:”C:nnWINDOWSnnsystem32nnrpcss.dll”:”ModuleHandle”:0x00000000. Using the API words, they generated a feature vector for each malware sample (By BoW approach with TF-IDF word weighting).
Feature selection
The paper applied DF-thresholding to eliminate very popular API words that appear in a majority of the malware samples. These API words are too generic to characterize a cluster of malware samples.
Non-negative Matrix Factorization (NMF)
NMF is an algorithm that factorizes a matrix into two matrices with the constraint that all three matrices have no negative elements. The advantage of NMF is that it can extract topics that can then be used as signatures for the task.
The key idea of NMF is to factorize the feature matrix X, i.e., X = TV.
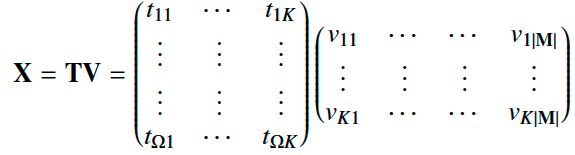
K is a parameter that controls the number of basis, which corresponds to clusters. The matrices T and V can be interpreted as the topic (basis) and the clustering results, respectively. This factorization can be obtained by minimizing the distance between the matrices X and TV:
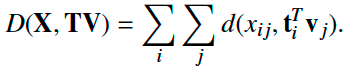
The paper adopt Kullback-Leibler(KL) divergence to compute the distance d:
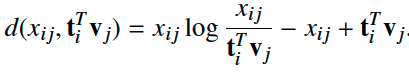
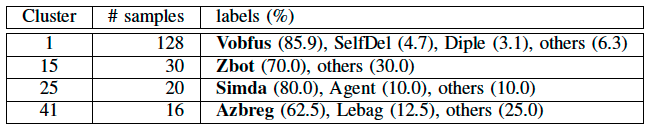
Result
The API call topics successfully extracted malware samples that had the similar intrinsic API calls. In addition, the detected malware samples were actually similar to each other because the majority of the detected samples have a single primary label in each cluster.
DeepSign: Deep Learning for Automatic Malware Signature Generation and Classification(2015)
The method uses a deep belief network (DBN), implemented with a deep stack of denoising autoencoders, generating an invariant compact representation of the malware behavior.
Feature
This paper used one of the simplest method of NLP to approach the sandbox files, that is, using unigram(1-gram) extraction. Furthermore, this paper in order to remain as domain agnostic as possible, they propose to treat the sandbox file as a simple text file, and extract unigrams without any preprocessing. That means, they omits all meaningless symbols and only pay attention to the words, for example, given “api”: “CreateFileW”, the terms extracted are “api”: and “CreateFileW”, completely ignoring what each part means.
In order to get the fixed size features, they proposed that:
- For each sandbox file in the dataset, extract all unigrams.
- Remove the unigrams which appear in all files (contain no information).
- For each unigram count the number of files in which it appears.
- Select top 20,000 with highest frequency.
- Convert each sandbox file to a 20,000 sized bit string, by checking whether each of the 20,000 unigrams appeared in it.
In their approach, they trained a deep denoising autoencoder consisting of eight layer: 20,000–5,000–2,500–1,000–500–250–100–30. At each step only one layer is trained, then the weights are “frozen”, and the subsequent layer is trained.
At the end of this training phase, they have a deep network which is capable of converting the 20,000 input vector into 30 floating point values. They regard these 30-sized vector as the “signature” of the program.
The process of DBN training looks like:
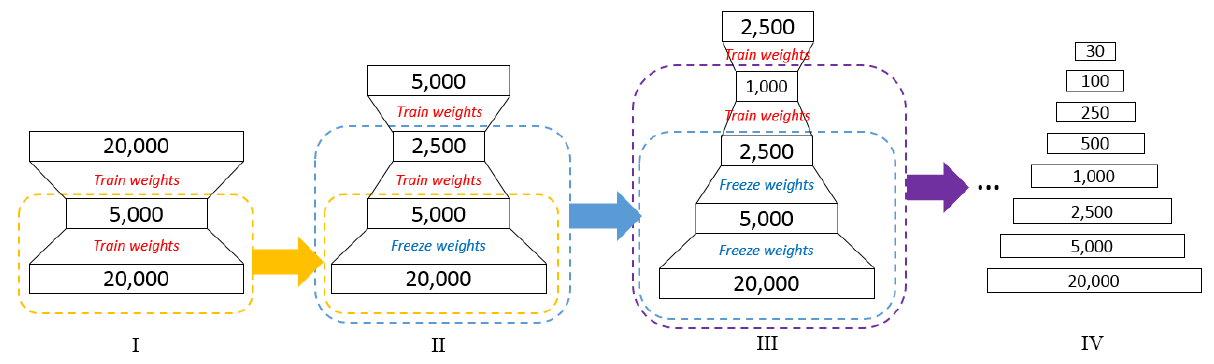
(I) Train the first autoencoder layer. (II) Use the weights from the previous layer, and build a new autoencoder on top of them. The weights taken from the first autoencoder are frozen. (III) Similarly, take the weights from the previous layer and add a new layer. (IV) Proceed with layer-wise training until training all the eight layers for the final DBN.
The all steps of this paper:
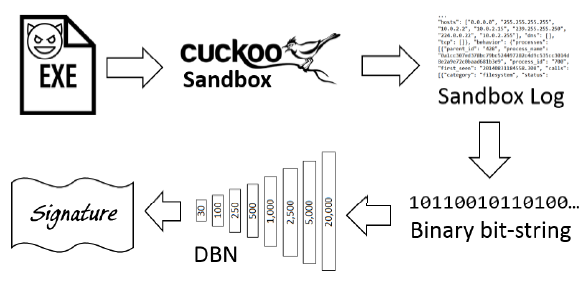
Some configuration:
- Each layer-wise training with a 0.5 dropout.
- Using ReLU as the activation function.
- 0.2 noise ratio, 0.001 learning rate then linearly decays to 0.000001, batch size of 20, and no momentum.
Dataset
Their dataset consists of six major categories of malware, and 300 variants in each category, for a total of 1,800 samples. The six malware categories used are Zeus, Carberp, Spy-Eye, Cidox, Andromeda, and DarkComet.
Experimental Results
- SVM with 96.4% accuracy.
- KNN with 95.3% accuracy.
- This paper’s DBN with 98.6% accuracy.
A Novel Approach to Detect Malware Based on API Call Sequence Analysis(2015)
This paper adopted DNA sequence alignment algorithms and extracted common API call sequence patterns of malicious function from malware in different categories. They indicated that two major approaches in dynamic analysis are control flow analysis and API call analysis. However, malware authors try to circumvent those techniques through inserting meaningless codes or shuffling the sequence of programs.
DNA Sequence Alignment
Sequence alignment algorithms are most widely used in the area of biometrics to calculate the similarity between two or more DNA sequences or to find certain DNA subsequences from full DNA.
Sequence alignment algorithms fall into two categories, which are global and local alignment. Global alignment aligns entire sequence. It is useful when they attempt to find the sequence of most similar length and strings. Local alignment finds the highly similar subsequences between given sequences.
Pairwise sequence alignment methods find global alignments or the locally similar subsequences of two sequences. Multiple sequence alignment algorithm extends pairwise alignment to handle multiple sequences at the same time. This paper applied multiple sequence alignment algorithm.
Environment Setup
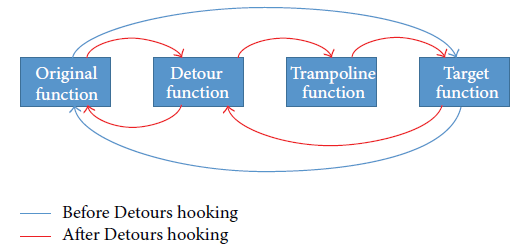
In this study, they used the Detours hooking library supported byMicrosoft to trace API call sequences from Windows executable programs. The Detours hooking process proceeds as shown in the following. Unlike the original process without Detours, the hooking process goes through the Detour function and the Trampoline function. This allows them to trace API call sequence.
For DNA sequence alignment, they used the ClustalX. ClustalX is widely used freeware in genome sequence analysis, such as DNA, RNA, or protein sequences. The program supports multiple sequence alignment (MSA) and also provides visualization.
In their dataset, 2,727 kinds of API were found; they categorized them into 26 groups according to MSDN library:
In our dataset, 2,727 kinds of API were found; they categorized them into 26 groups according to MSDN library:

To extract the common API call sequence pattern among malware, the longest common subsequences (LCSs) were used. LCS shows the longest malware API call sequence pattern, it can be treated as a malware’s signature. For example, the LCSs of ABCD and ACB are AB and AC:
Furthermore, they excluded these typical LCSs reduce false positive error since some benign programs share same API calls sequence. They employed an additional feature. They assumed that there exists a specific API call sequence pattern that matches specific malicious activity. If such an API call sequence pattern exists, they can detect unknown attacks by checking whether a critical API call sequence pattern exists. For example:

It should be noted that round brackets represent the OR relation. For example, in the case of IAT hooking, one possible critical API call sequence pattern is [LoadLibrary, strcmp, VirtualProtect]. They believe that this behavior-based malware classification can be effective in the dynamic analysis of API call sequences.
The overall process as following:
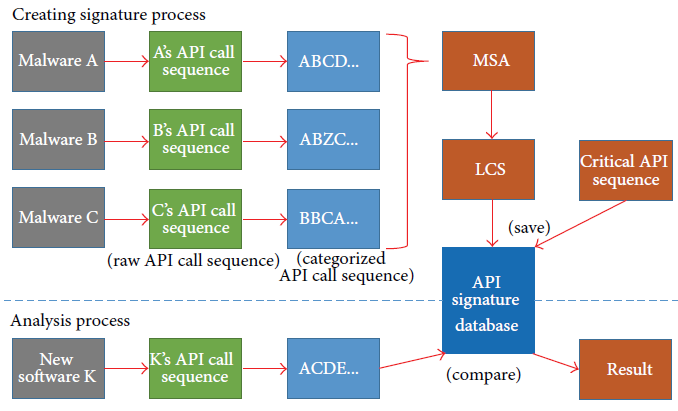
In the analysis process, the extracted API call sequence of a newly inserted program is compared with the API signatures in the database. If any LCS ismatched with the signatures, the newly inserted program is classified as malware.
Experiment result
To summarize, the precision is 1, FPR is 0, and recall is 0.998. The 𝐹1 score is 0.999.

MALWARE CLASSIFICATION WITH RECURRENT NETWORKS(2015)
This paper proposed a different approach, which, similar to natural language modeling, learns the language of malware spoken through the executed instructions and extracts robust, time domain features. Echo state networks (ESNs) and recurrent neural networks (RNNs) are used for the projection stage that extracts the features.
Specifically, using the recurrent model to directly classify the files is not efficient (there is only a single bit of information for every sequence). Instead, they use a recurrent model trained to predict next API call, and use the hidden state of the model (that encodes the history of past events) as the fixed-length feature vector that is given to a separate classifier (logistic regression or MLP).
The overall process as following:
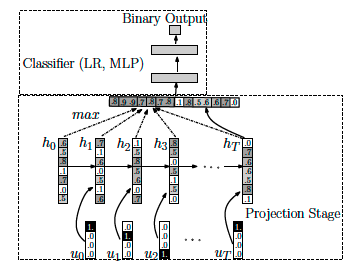
ut and ht demote the input and state vectors. At each state, they apply a recurrent neural network operation to the input and get a hidden vector ht. Then they apply a max-pooling to get a feature vector, then, applying a MLP or logistic regression to do the classification on the feature vector
Finally, they got TPR 71.71% at FPR 0.1%.
Malware Characterization using Windows API Call Sequences(2016)
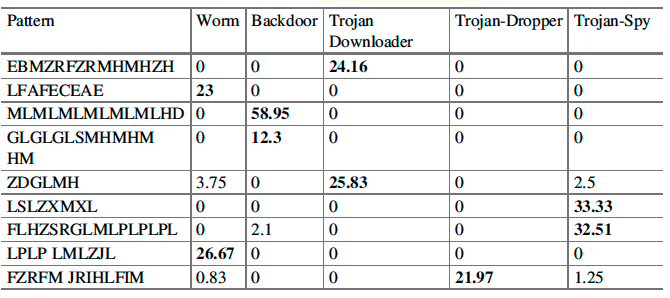
This paper proposed a hashed method to identify the category of malware. First, they chose a total set of 534 important Win-APIs have been hooked and mapped to 26categories (A…Z). Then they used Fuzzy hashing algorithm ssdeep to generate fuzzy hash based signature. These signatures were matched to quantify the API call sequence homologies between test samples and training samples.
The overall process as following:
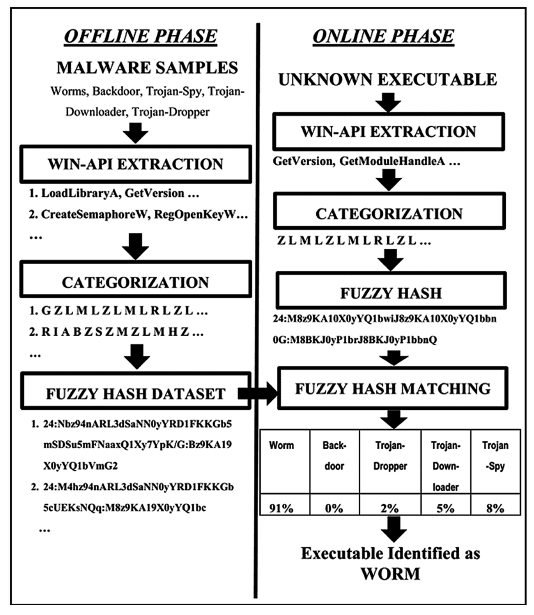
Categorization of Win-API Calls
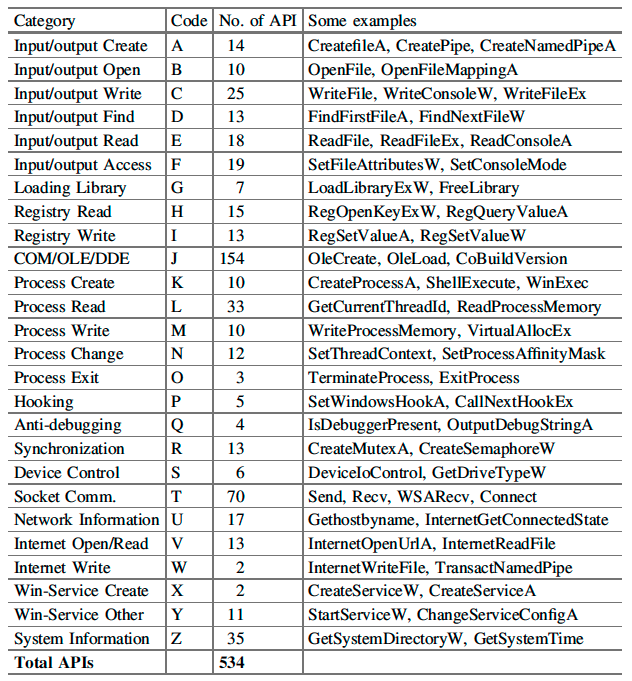
This paper have categorized the total set of 534 Win-API calls into 26 Categories based upon the function these APIs are performing.
Fuzzy Hash Signatures
This paper applied ssdeep program to compute Context Triggered Piecewise Hash (CTPH), also called fuzzy hash, on the categorized API call sequences.
The concept of fuzzy hashing has been used as it has the capability to compare two different samples and determine the level of similarity between them. Instead of generating a single hash for a file, piecewise hashing generates many hashes for a file based on different sections of the file. CTPH algorithm uses the rolling hash to determine the start and stop of each segment. CTPH Signature generation algorithm combines these section hashes in a particular way to generate the fuzzy hash of the file.
They selected this technique because CTPH can match inputs that have homologies and these sequences may be different in both content and length.

Ssdeep matching algorithm calculates the matching between fuzzy hashes of two different samples. This score is based on the edit distance algorithm: Damerau Levenshtein Distance between two strings. After matching a comparison score is generated between 0 and 100. they have used this matching score as malware classification criteria.
Result
Following table gives the classification accuracy and FPR for these five 2-class problems.
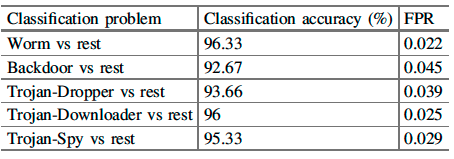
In addition, this table gives the accuracy & FPR for 2 class classifier problems (Malware vs Benign).
Deep Learning LSTM based Ransomeware Detection(2017)
This paper aims to detect ransomware behavior by employing Long-Short Term Memory (LSTM) networks for binary sequence classification of API calls. They present an automated approach to extract API calls from the log of modified sandbox environment and detect ransomware behavior.
Ransomware are malicious software designed to deny access to a computer system or computer resource. There are two categories of ransomware: Crypto ransomware and locker ransomware. Locker ransomware try to lock access to the system user interface. Crypto ransomware on the other hand, deny access to user ata using strong encryption algorithms.
API call extraction
This paper used a cuckoo-modified since it has provided more anti-anti sandbox features than the standard version. Also, the timeout value for analysis has been extended to 20 minutes to defeat delayed execution strategies employed by some malwares authors.
The overall process as following:
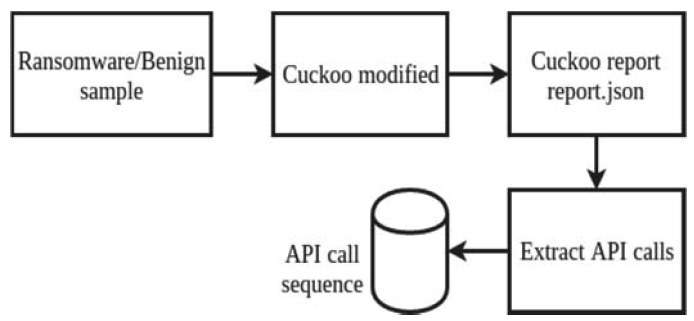
LSTM
This paper picked up 38 APIs which were common in all the samples. And then labeled them as an integer between 1 and 39. Each process had a different length of API sequence. After the conversion to integer, 0s were appended to the sequences to match the length of the longest sequence of length 779980.
Finally, they received an experimental accuracy of 96.67%.
NEURAL SEQUENTIAL MALWARE DETECTION WITH PARAMETERS(2018)
This paper extend previous work, they said the previous LSTM model only considered the API calls sequence but ignored its parameters. So they extend this model to include each system API call’s two most input parameters.
Due to the variation in the structure and size of the vocabulary, this paper used these parameters in a limited character space. They used these parameters by learning character grams from them. They built n-grams over these characters in the corpus, and only extract the top-K by the frequency distribution.
The process of constructing character grams as following:

Then by using the following two algorithms, they converted the n-grams to indexed vector.


Then they applied tanh to each vectored parameter, finally concatenate each API calls name with its parameters together.
The overall process as following:
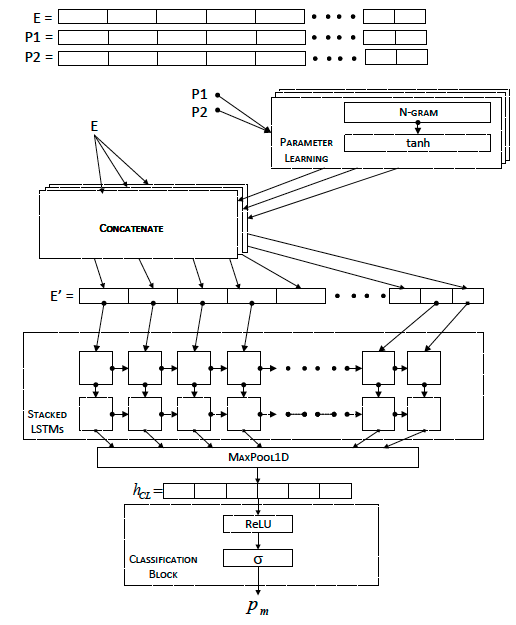
The LSTM process looks like the above paper, which used a maxpooling to extract feature from each stage of LSTM, then applied a logistic regression followed by a ReLU and sigmoid.
Result
They collected the system API calls and their parameters from 75,000 files, which were evenly split between malware and benign files, in September 2017. The data from all of the files is unique, and there is a total of 158 event types in our data.
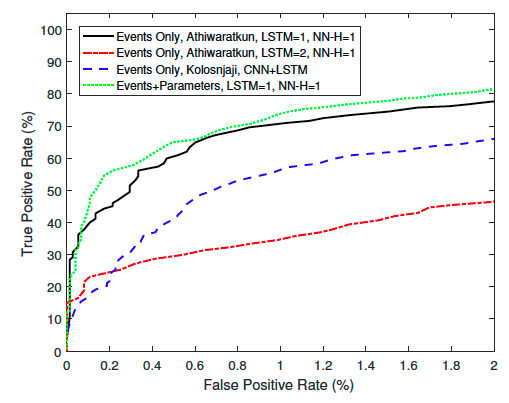
Comparison of the ROC curves for two versions of the Events Only LSTM+NN model, the Events Only CNN+LSTM model, and the proposed Events + Parameters model as following: