
RCMD Industry Paper
Outline
- Feature Interaction
- User Behaviour
- Long-term User Behaviour
- Multi Task
- Multi Domain
- Multi-Modal
- Deep Match
- Bias
- List Wise
Other Papers
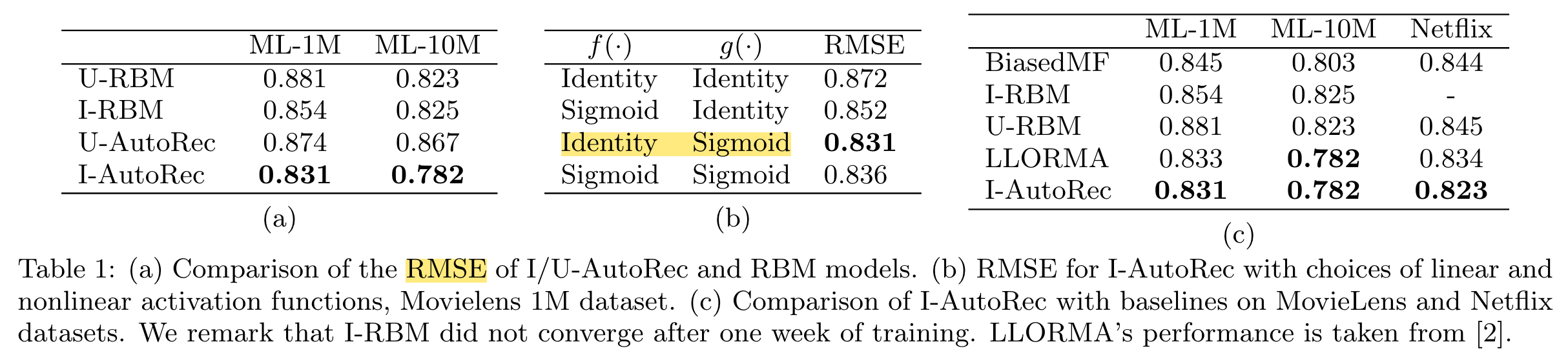
AutoRec
(2015)
AutoRec, a new CF model based on the autoencoder paradigm.
In rating-based collaborative filtering, we have m users, n items, and a partially observed user-item rating matrix R ∈ Rm×n.
Our aim in this work is to design an item-based (user-based) autoencoder which can take as input each partially observed r(i) (r(u)), project it into a low-dimensional latent (hidden) space, and then reconstruct r(i) (r(u)) in the output space to predict missing ratings for purposes of recommendation.
h(r; θ) = f (W · g(Vr + μ) + b)
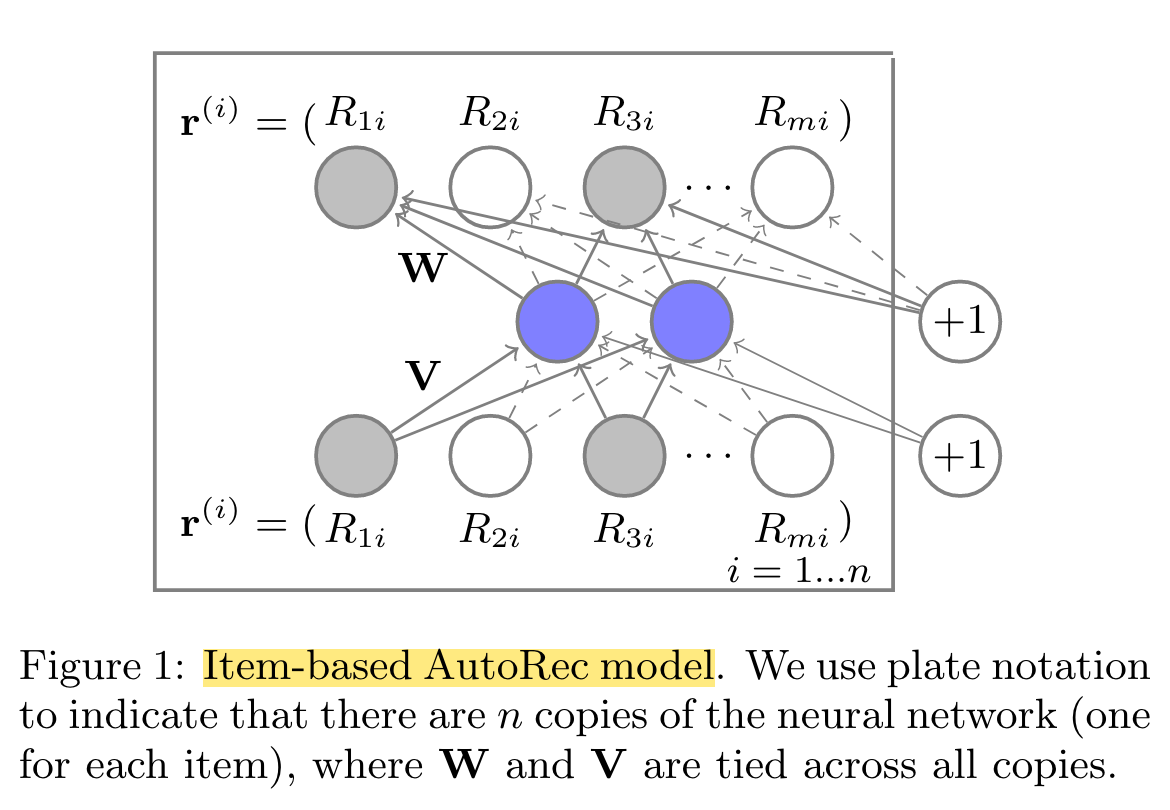
- First, we account for the fact that each r(i) is partially observed by only updating during backpropagation those weights that are associated with observed inputs, as is common in matrix factorisation and RBM approaches.
- Second, we regularise the learned parameters so as to prevent overfitting on the observed ratings.
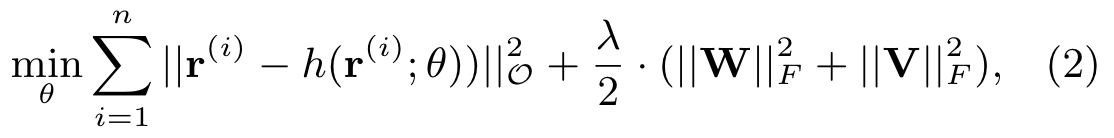
regularisation strength λ > 0
Deep Crossing
(2016)
This paper proposes the Deep Crossing model which is a deep neural network that automatically combines features to produce superior models.
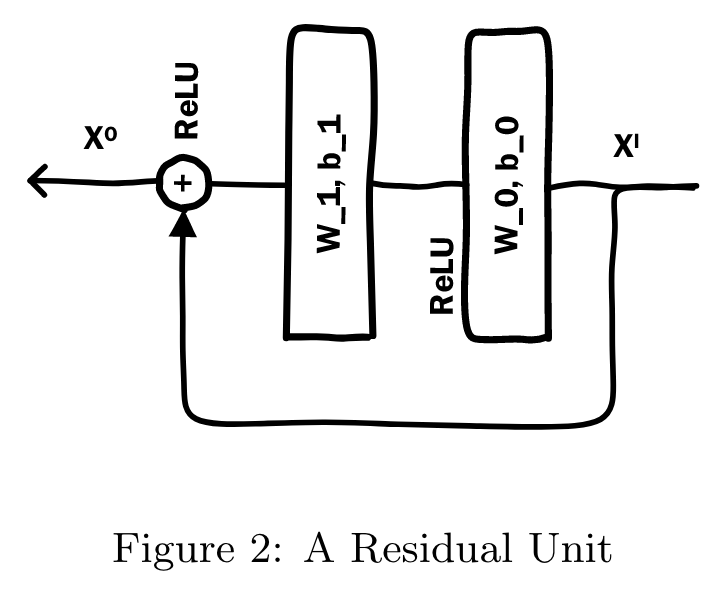
The important crossing features are discovered implicitly by the networks, which are comprised of an embedding and stacking layer, as well as a cascade of Residual Units.
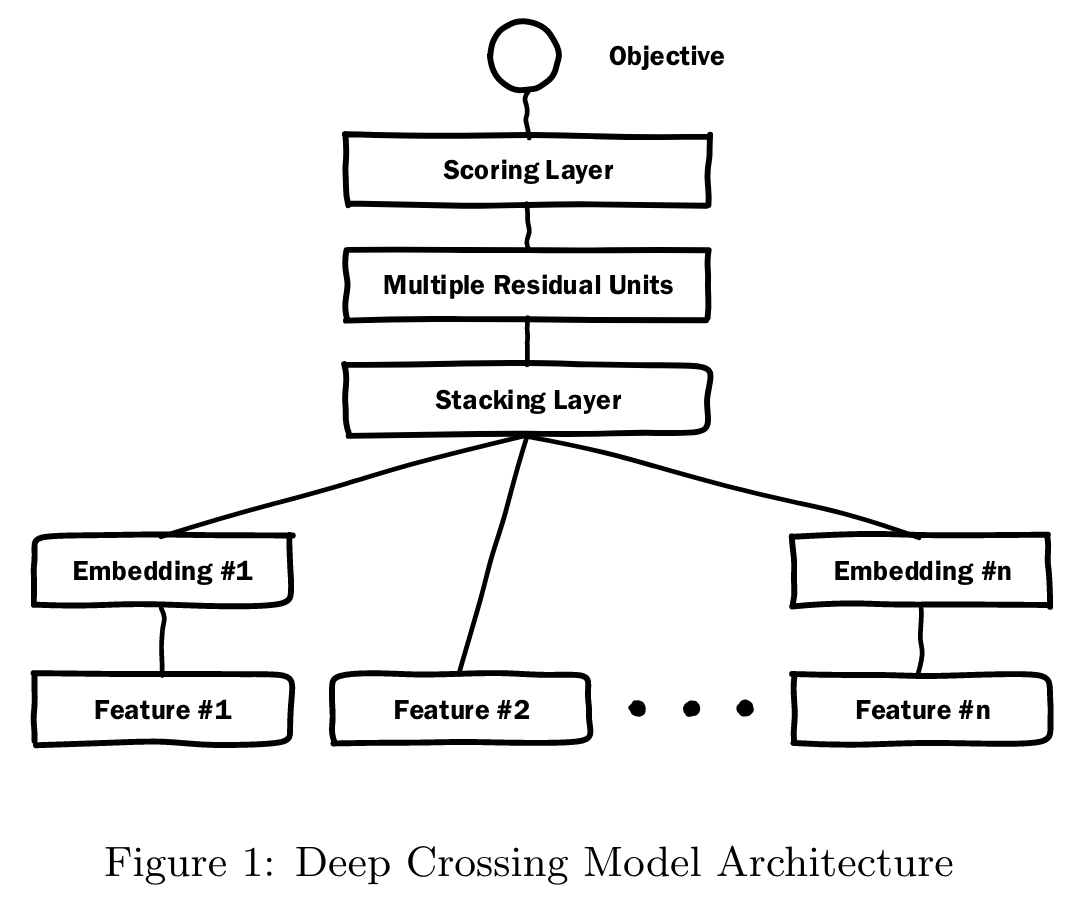
Embedding and Stacking Layers, Embedding is applied per individual feature to transform the input features.
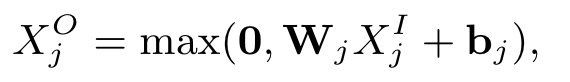
Residual Layers
Neural CF
(2017)
In this work, we strive to develop techniques based on neural networks to tackle the key problem in recommendation — collaborative filtering — on the basis of implicit feedback.
By replacing the inner product with a neural architecture that can learn an arbitrary function from data, we present a general framework named NCF, short for Neural networkbased Col laborative Filtering.
Among the various collaborative filtering techniques, matrix factorization (MF) [14, 21] is the most popular one, which projects users and items into a shared latent space, using a vector of latent features to represent a user or an item. Thereafter a user’s interaction on an item is modelled as the inner product of their latent vectors.
Despite the effectiveness of MF for collaborative filtering, it is well-known that its performance can be hindered by the simple choice of the interaction function inner product.
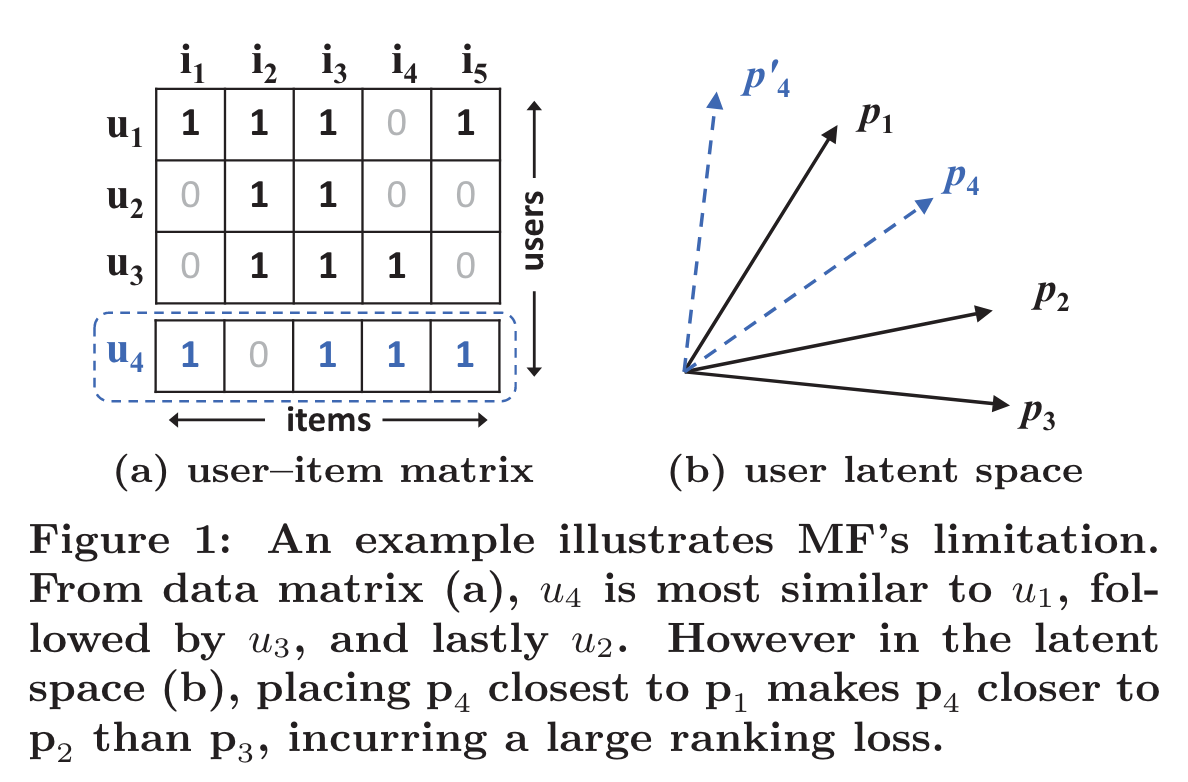
This paper explores the use of deep neural networks for learning the interaction function from data.
General Framework
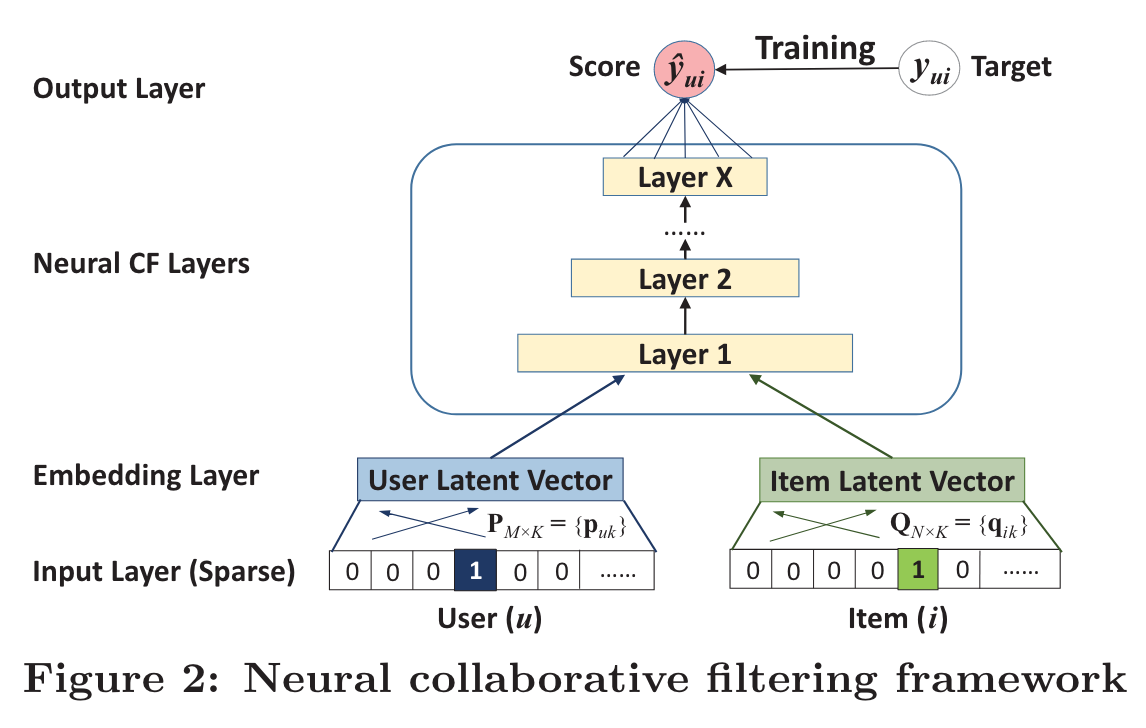
Above the input layer is the embedding layer; it is a fully connected layer that projects the sparse representation to a dense vector
Fusion of GMF and MLP, Generalized Matrix Factorization (GMF)
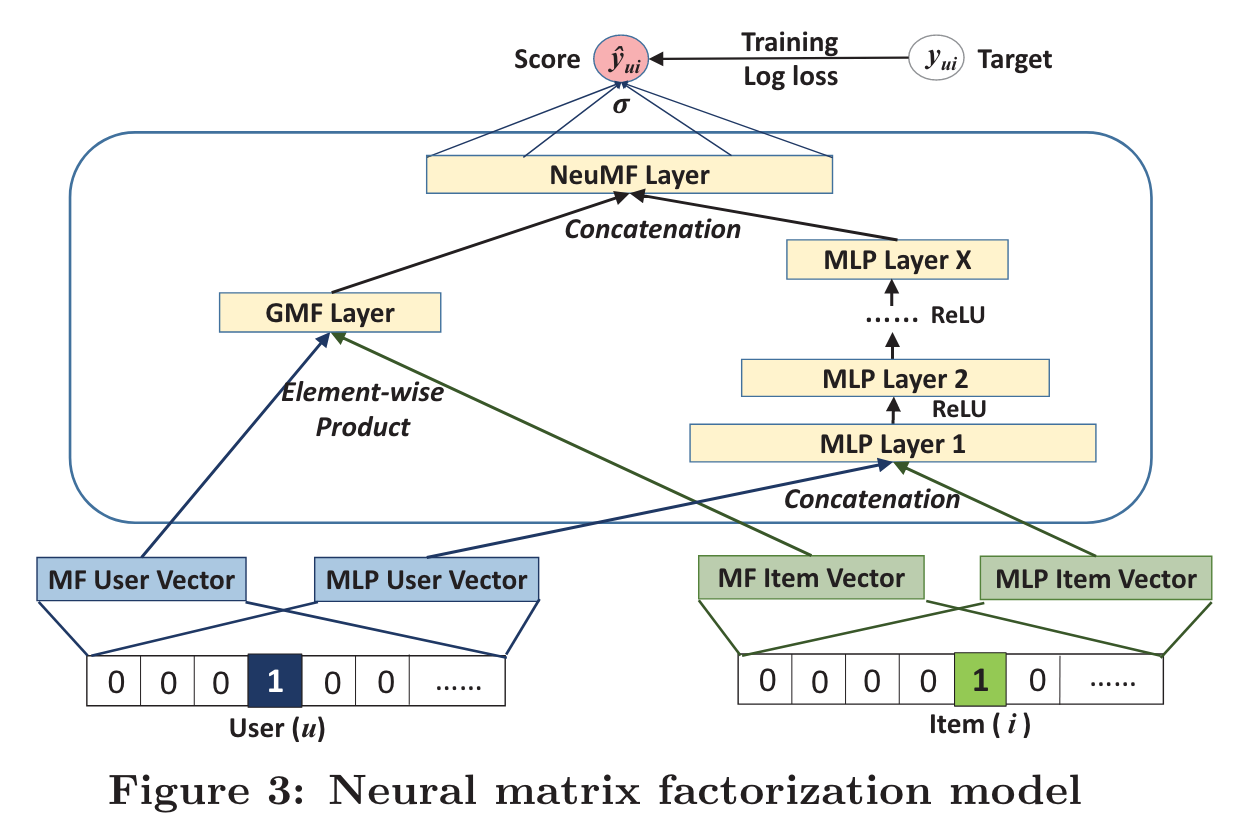
We first train GMF and MLP with random initializations until convergence. We then use their model parameters as the initialization for the corresponding parts of NeuMF’s parameters.
PNN
(2016)
In this paper, we propose a Product-based Neural Networks (PNN) with an embedding layer to learn a distributed representation of the categorical data, a product layer to capture interactive patterns between interfield categories, and further fully connected layers to explore high-order feature interactions.
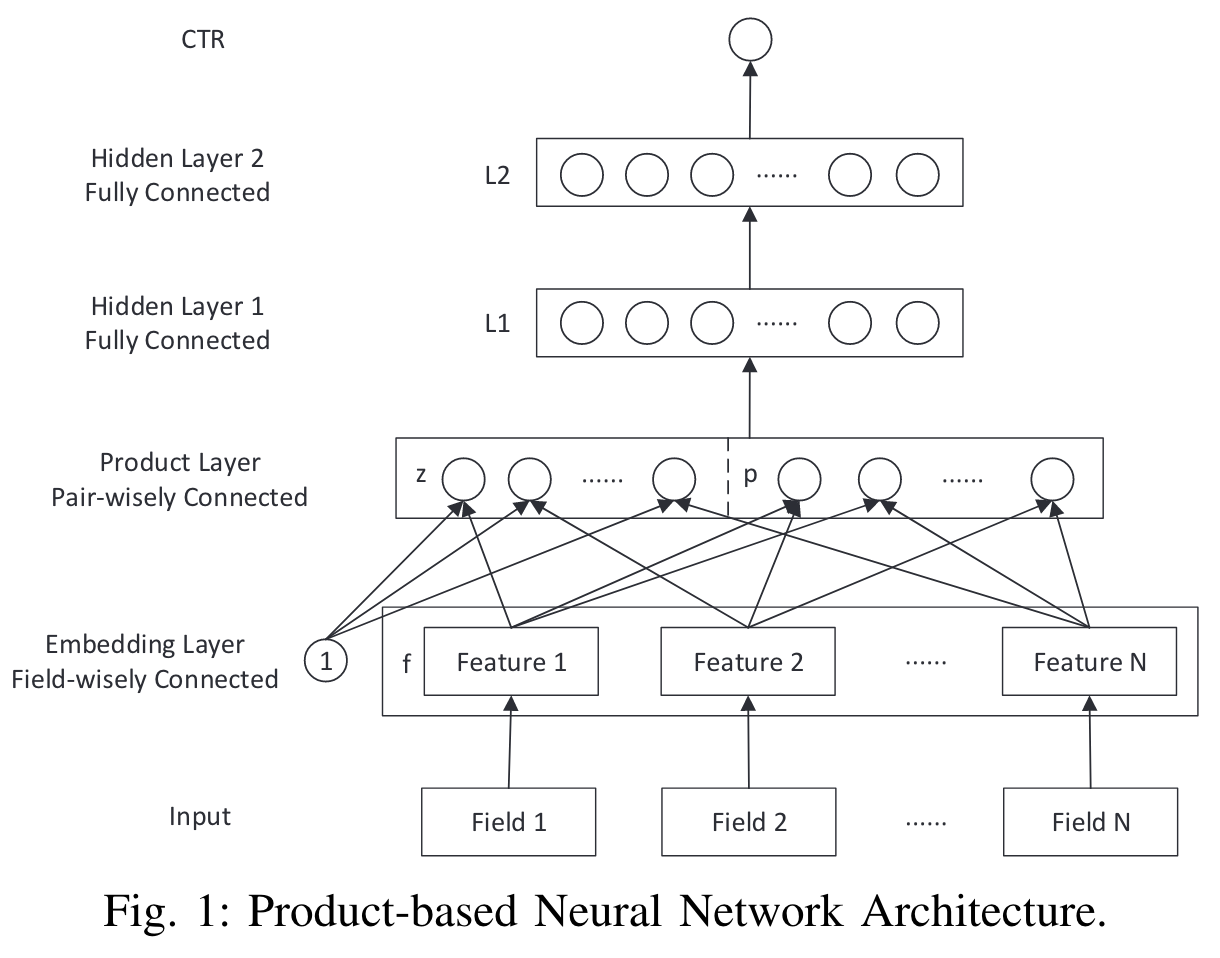
Product-based Neural Network (PNN):
builds a product layer based on the embedded feature vectors to model the inter-field feature interactions
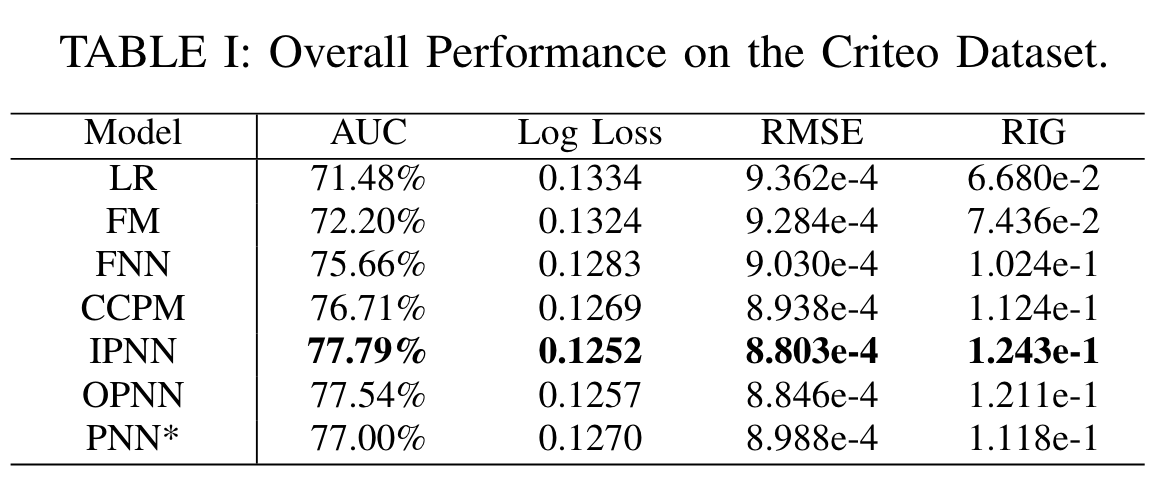
In this paper, we propose two variants of PNN, namely IPNN and OPNN,
Inner Product-based Neural Network (IPNN), which takes a pair of vectors as input and outputs a scalar.
Outer Product-based Neural Network (OPNN), which takes a pair of vectors and produces a matrix.
Wide&Deep
(2016)
One challenge in recommender systems, similar to the general search ranking problem, is to achieve both memorization and generalization.
Memorization can be loosely defined as learning the frequent co-occurrence of items or features and exploiting the correlation available in the historical data. Generalization, on the other hand, is based on transitivity of correlation and explores new feature combinations that have never or rarely occurred in the past.
Memorization can be achieved effectively using cross-product transformations over sparse features. One limitation of cross-product transformations is that they do not generalize to query-item feature pairs that have not appeared in the training data.
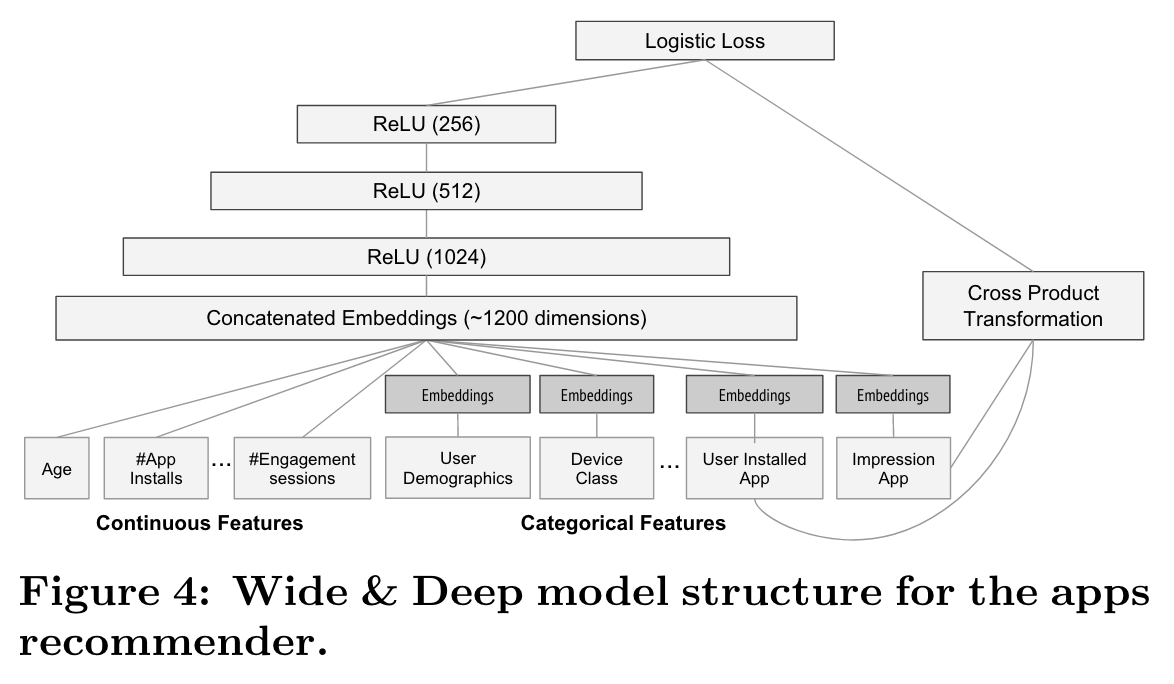
The combined model’s prediction is:
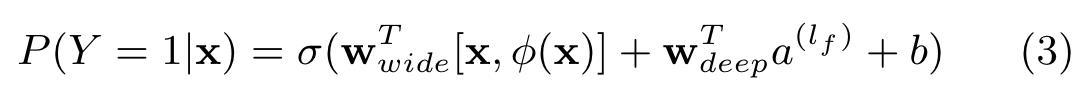
Performance
DeepFM
(2017)
The proposed model, DeepFM, combines the power of factorization machines for recommendation and deep learning for feature learning in a new neural network architecture.
Compared to the latest Wide & Deep model from Google, DeepFM has a shared input to its “wide” and “deep” parts, with no need of feature engineering besides raw features.
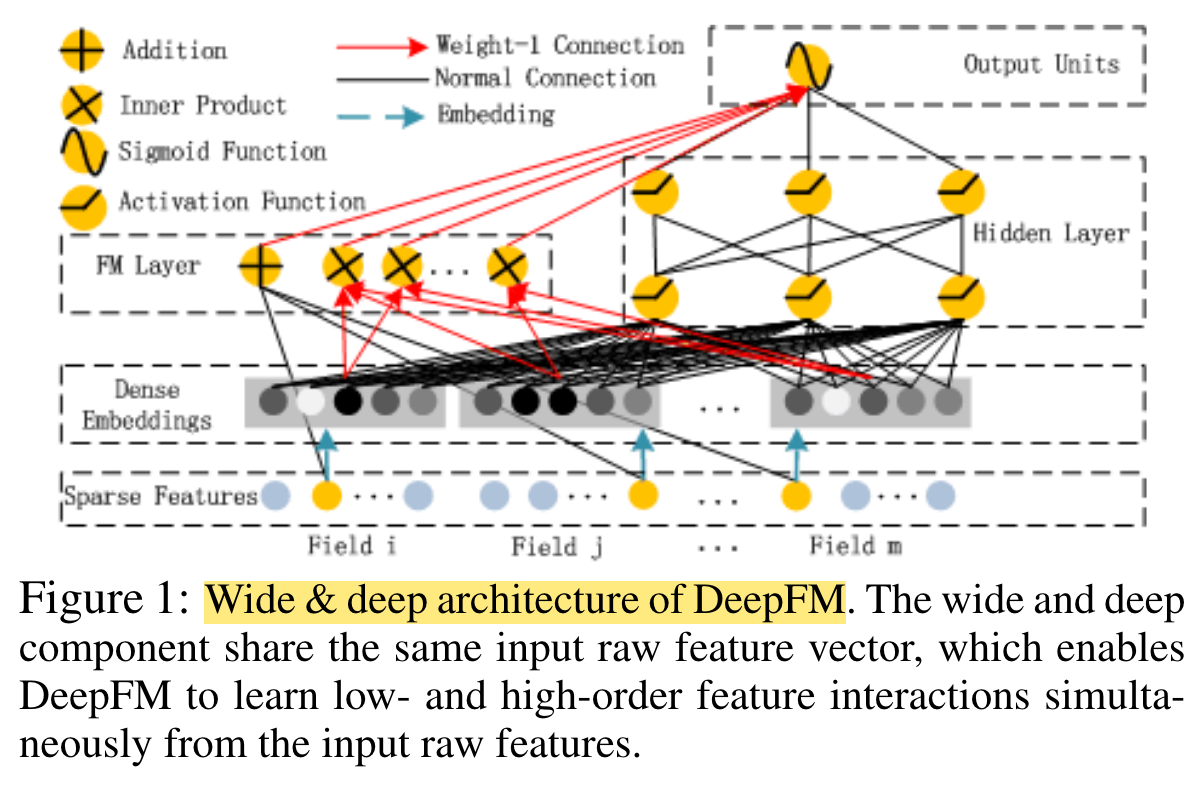
FM Component
The output of FM is the summation of an Addition unit and a number of Inner Product units
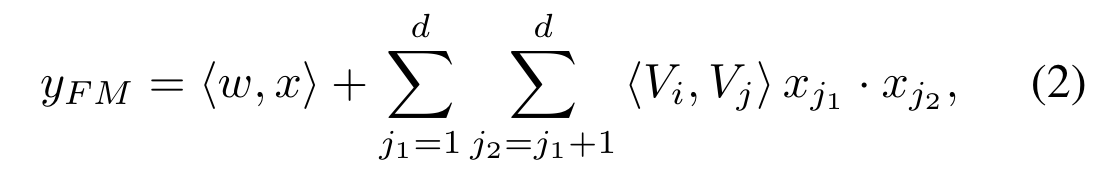
Deep Component
The deep component is a feed-forward neural network, which is used to learn high-order feature interactions.
Embedding
It is worth pointing out that FM component and deep component share the same feature embedding
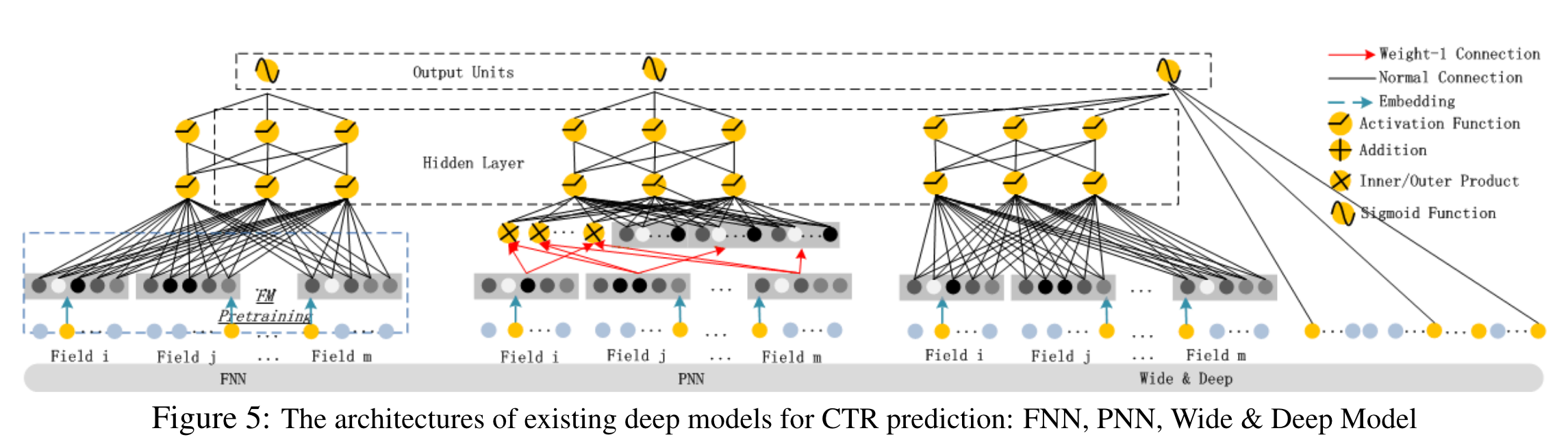
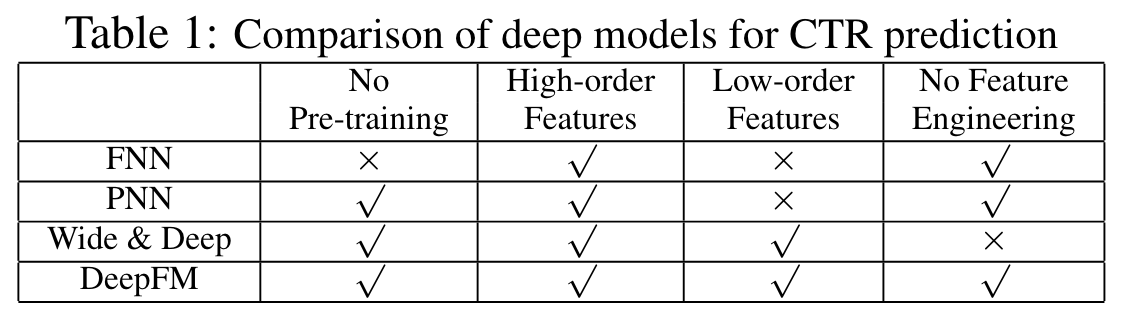
Relationship with the other Neural Networks
FNN, PNN, Wide&Deep
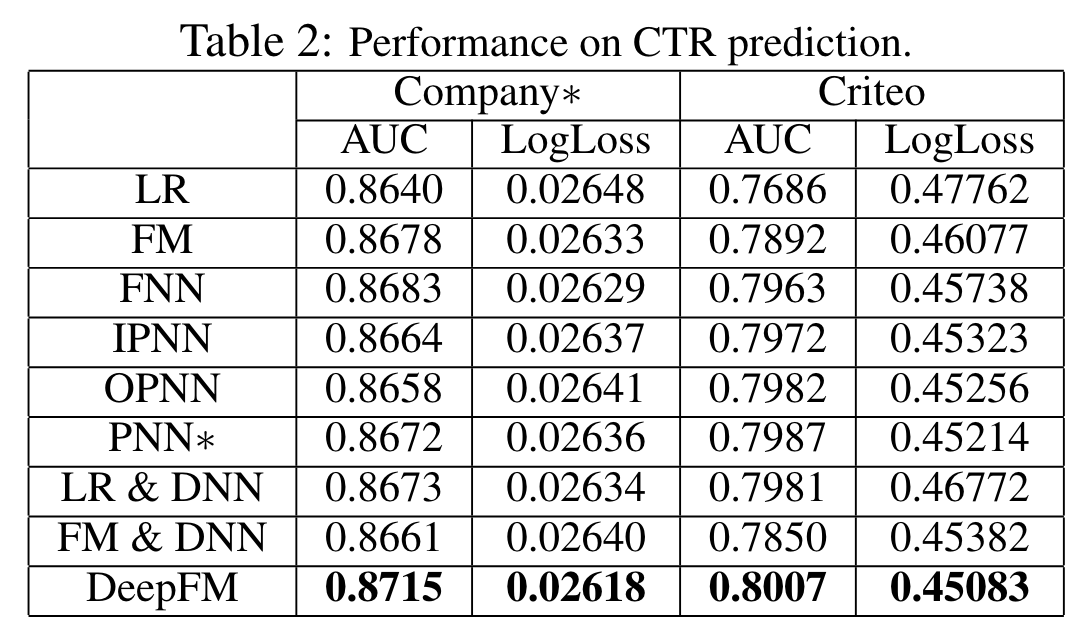
Performance
DCN
(2017)
In this paper, we propose the Deep & Cross Network (DCN) which keeps the benefits of a DNN model, and beyond that, it introduces a novel cross network that is more efficient in learning certain bounded-degree feature interactions.
In the Kaggle competition, the manually craed features in many winning solutions are low-degree, in an explicit format and effective.
The wide-and-deep [4] is a model in this spirit. It takes cross features as inputs to a linear model, and jointly trains the linear model with a DNN model.
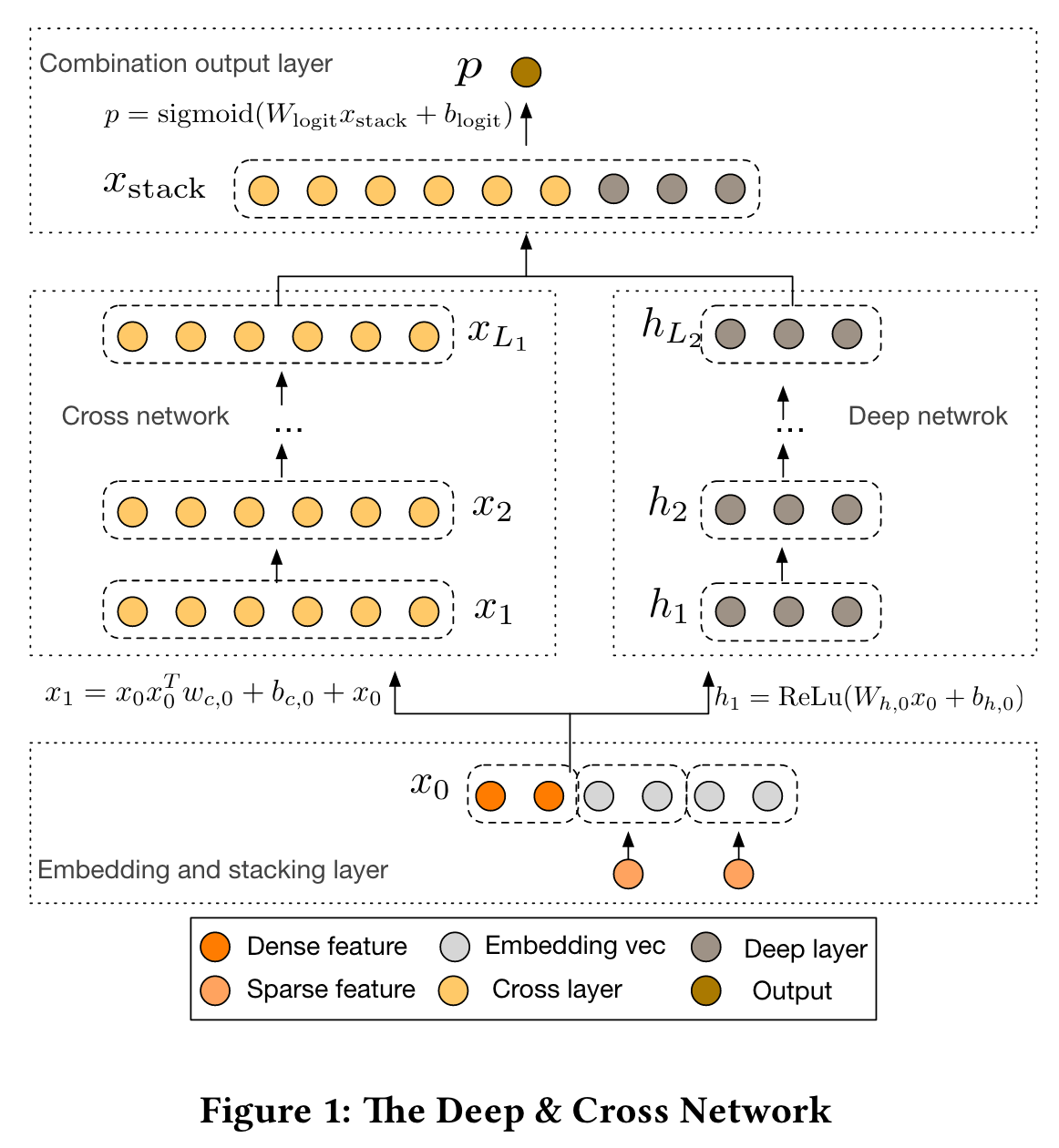
Embedding and Stacking Layer: Embedding matrix & embedding vector
Cross Network
The cross network is composed of cross layers, with each layer having the following formula:
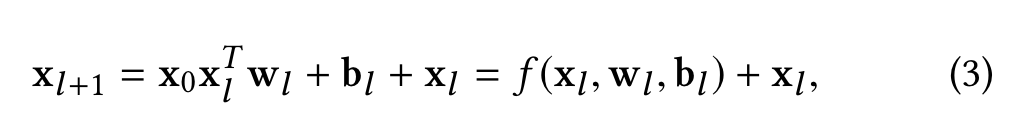
A visualization of one cross layer is shown in Figure 2.
Performance

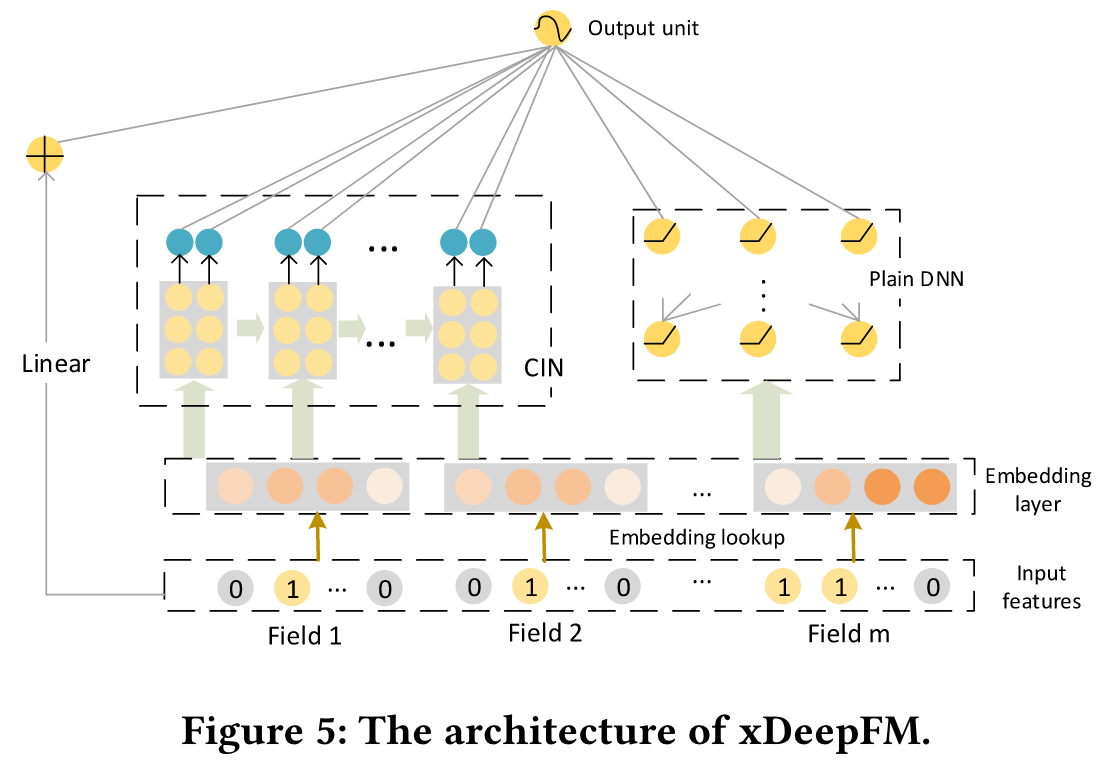
xDeepFM
(2018)
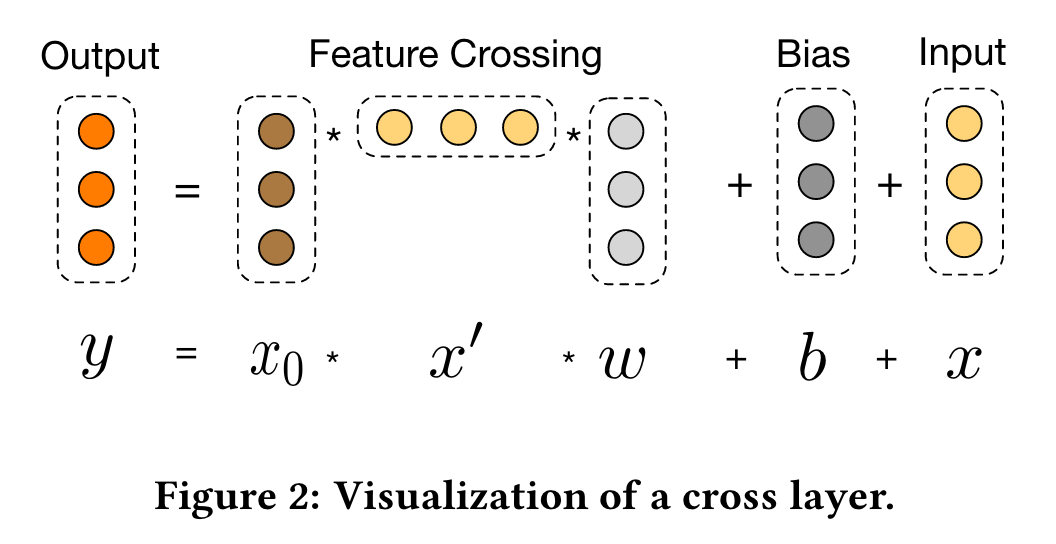
In this paper, we propose a novel Compressed Interaction Network (CIN), which aims to generate feature interactions in an explicit fashion and at the vector-wise level.
In this paper, we propose a novel Compressed Interaction Network (CIN), which aims to generate feature interactions in an explicit fashion and at the vector-wise level.
We thus design a novel compressed interaction network (CIN) to replace the cross network in the DCN.
Embedding Layer
Implicit High-order Interactions: Wide&Deep
Explicit High-order Interactions: DCN
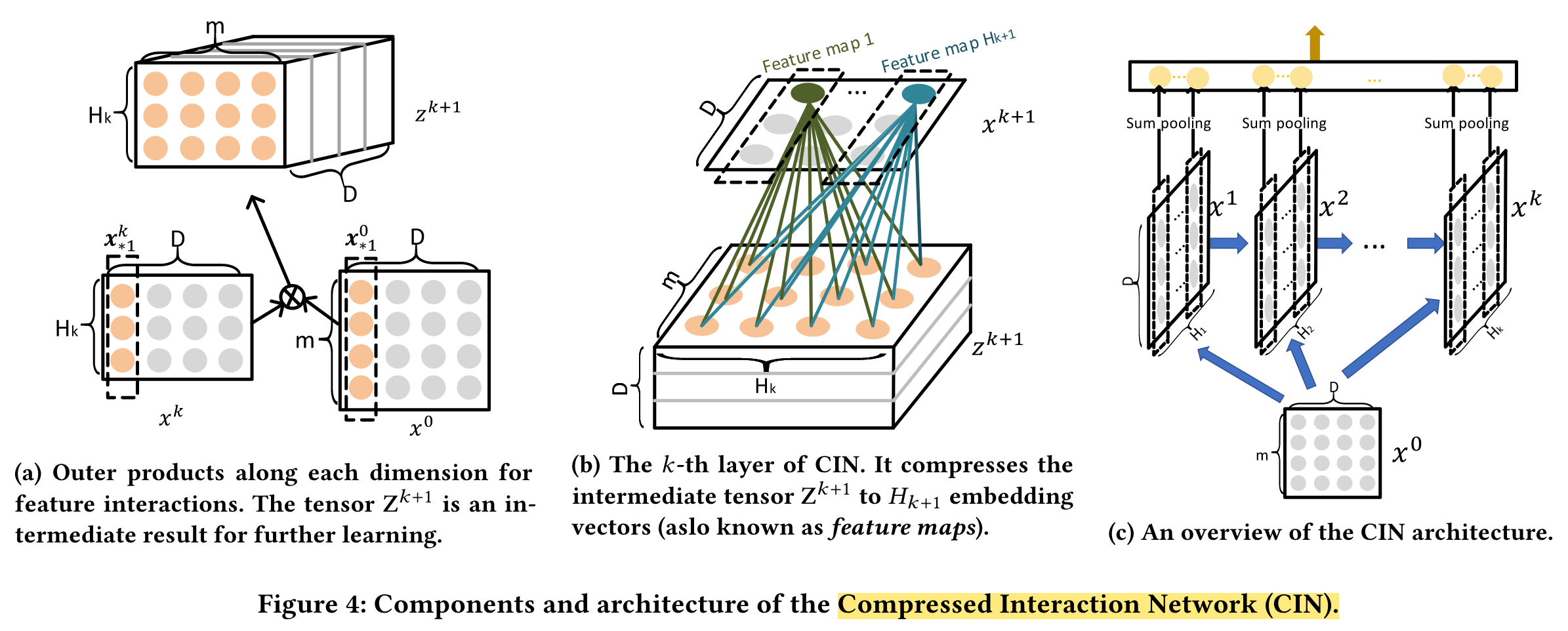
Compressed Interaction Network (CIN), with the following considerations:
(1) interactions are applied at vector-wise level, not at bit-wise level;
(2) high-order feature interactions is measured explicitly;
(3) the complexity of network will not grow exponentially with the degree of interactions.
we formulate the output of field embedding as a matrix X0 ∈ Rm×D, where the i-th row in X0 is the embedding vector of the i-th field.
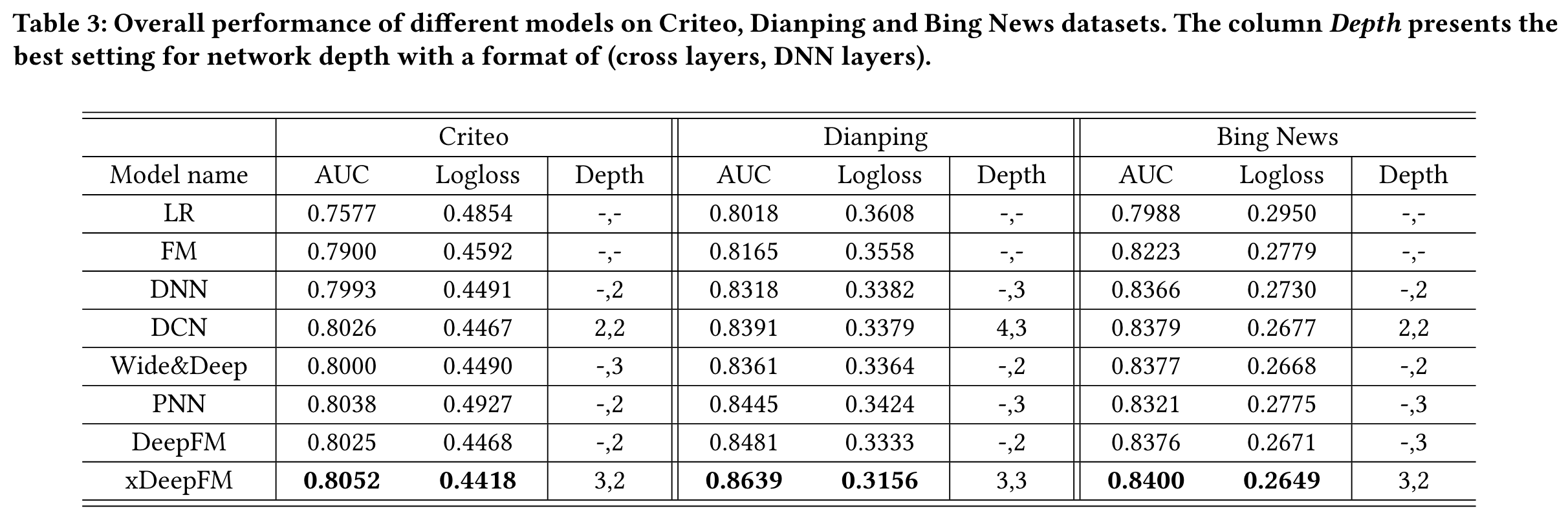
Performance
NFM
(2017)
In this work, we propose a novel model for sparse data prediction named Neural Factorization Machines (NFMs), which enhances FMs by modelling higher-order and non-linear feature interactions.
By devising a new operation in neural network modelling — Bilinear Interaction (Bi-Interaction) pooling — we subsume FM under the neural network framework for the first time.
Expressiveness Limitation of FM: FM still belongs to the family of (multivariate) linear models.
The NFM Model
Bi-Interaction Layer
Clearly, the output of Bi-Interaction pooling is a k-dimension vector that encodes the second-order interactions between features in the embedding space.
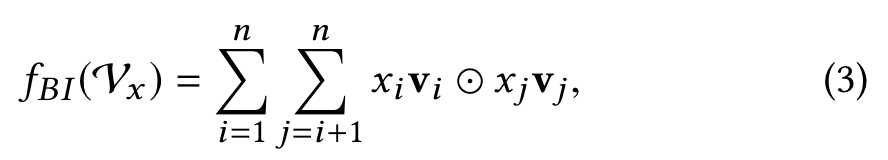
AFM
(2017)
We propose a novel model named Attentional Factorization Machine (AFM), which learns the importance of each feature interaction from data via a neural attention network
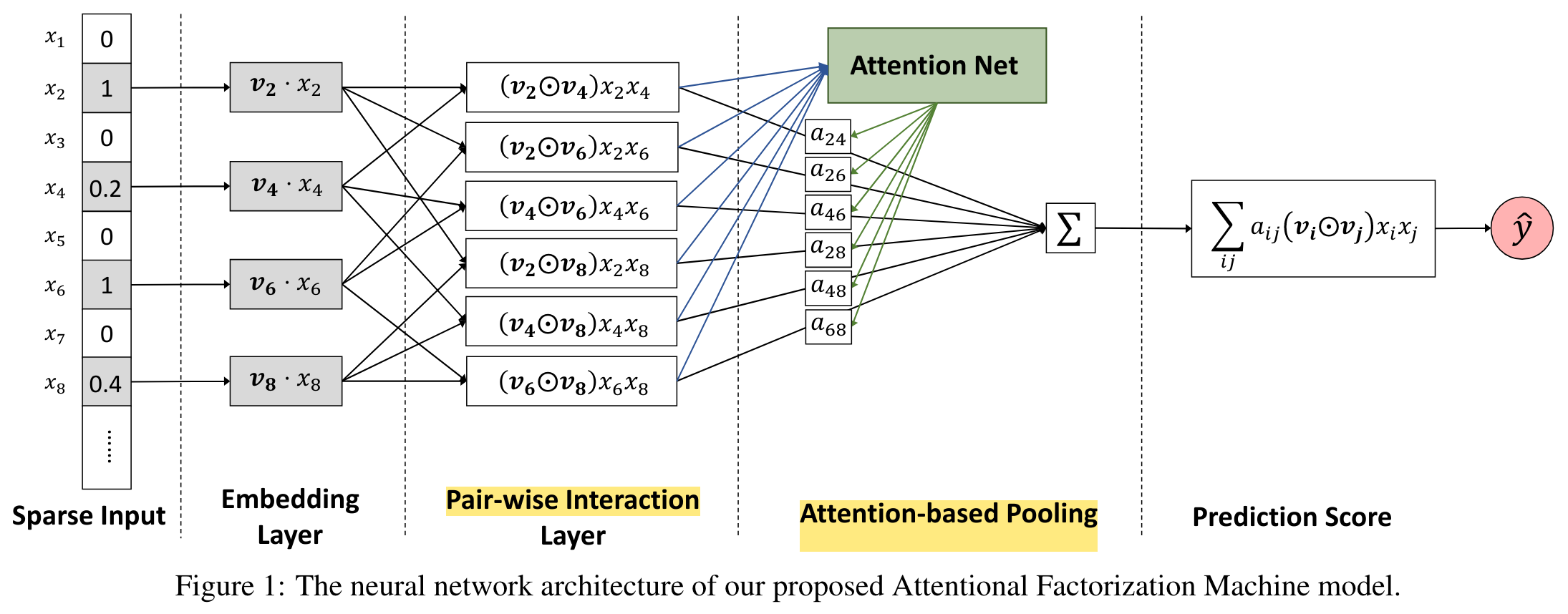
Pair-wise Interaction Layer
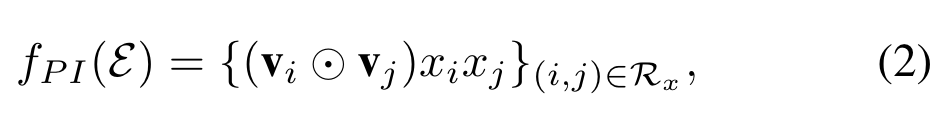
Attention-based Pooling Layer
We propose to employ the attention mechanism on feature interactions by performing a weighted sum on the interacted vectors:
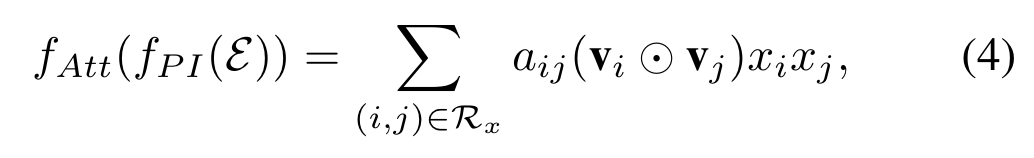
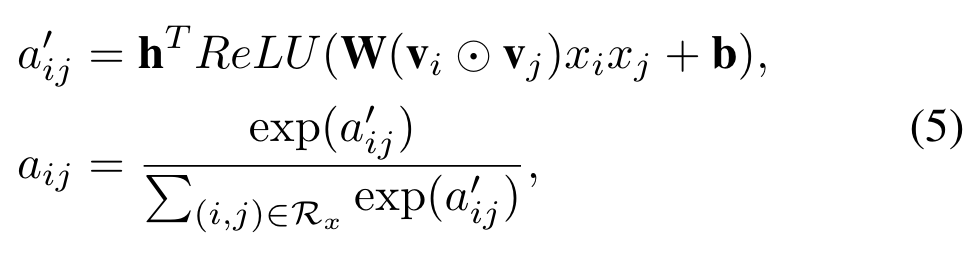
DIN
(2018)
In this paper, we propose a novel model: Deep Interest Network (DIN) which tackles this challenge by designing a local activation unit to adaptively learn the representation of user interests from historical behaviors
It is not necessary to compress all the diverse interests of a certain user into the same vector when predicting a candidate ad because only part of user’s interests will influence his/her action (to click or not to click).
Besides, we develop two techniques: mini-batch aware regularization and data adaptive activation function which can help training industrial deep networks with hundreds of millions of parameters.
In this paper, we develop a novel mini-batch aware regularization where only parameters of non-zero features appearing in each mini-batch participate in the calculation of L2-norm, making the computation acceptable.
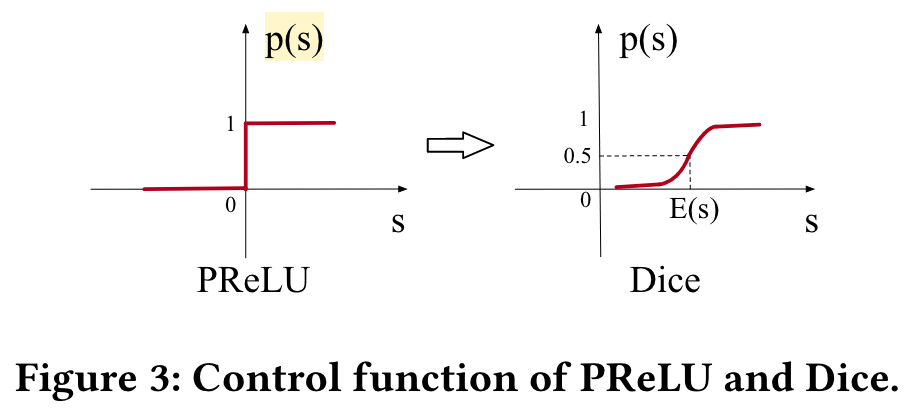
Besides, we design a data adaptive activation function, which generalizes commonly used PReLU[12] by adaptively adjusting the rectified point w.r.t. distribution of inputs and is shown to be helpful for training industrial networks with sparse features.
DIN designs a local activation unit to soft-search for relevant user behaviors and takes a weighted sum pooling to obtain the adaptive representation of user interests with respect to a given ad.
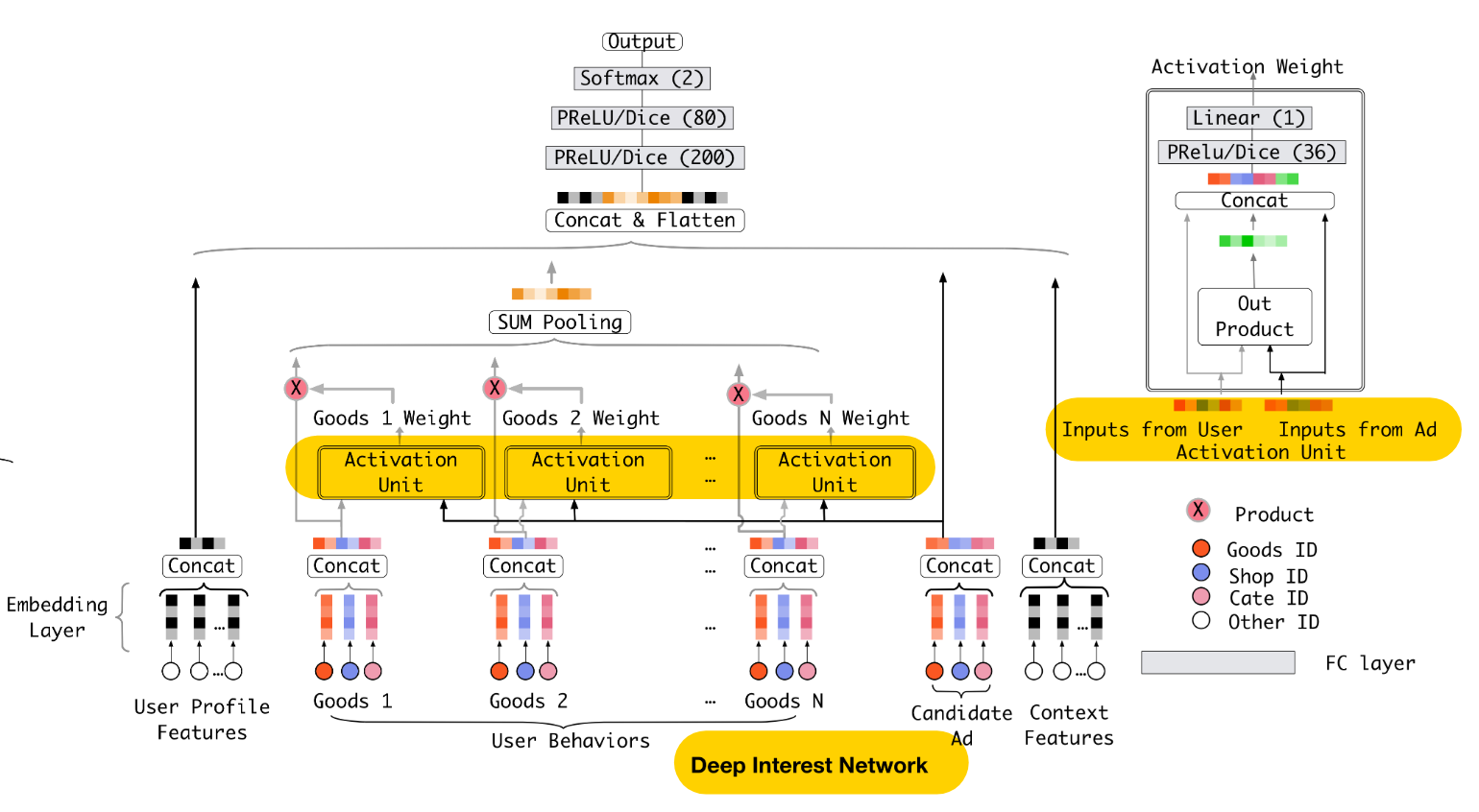
Local activation unit of Eq.(3) shares similar ideas with attention methods which are developed in NMT task[1]. However different from traditional attention method, the constraint is relaxed in Eq.(3), aiming to reserve the intensity of user interests. That is, normalization with softmax on the output of a(·) is abandoned.
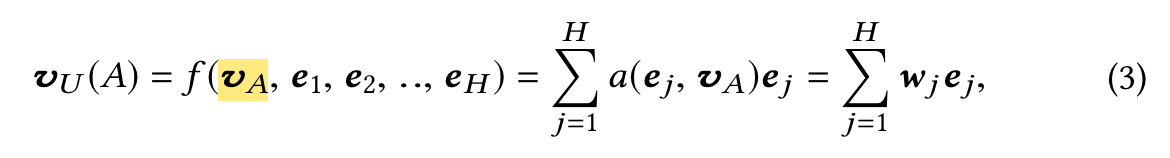
Mini-batch Aware Regularization
In this paper, we introduce an efficient mini-batch aware regularizer, which only calculates the L2-norm over the parameters of sparse features appearing in each mini-batch and makes the computation possible.
Data Adaptive Activation Function
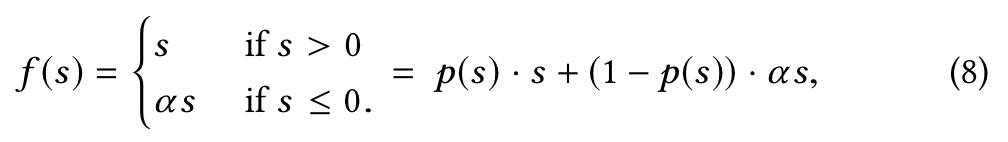
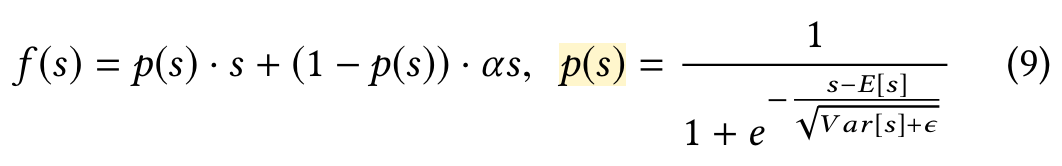
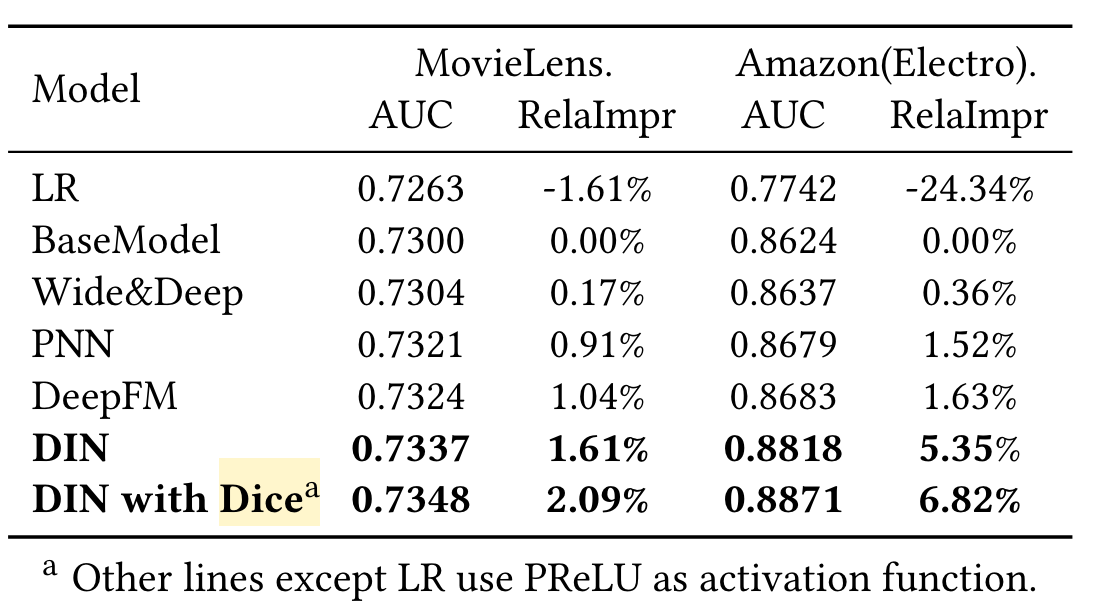
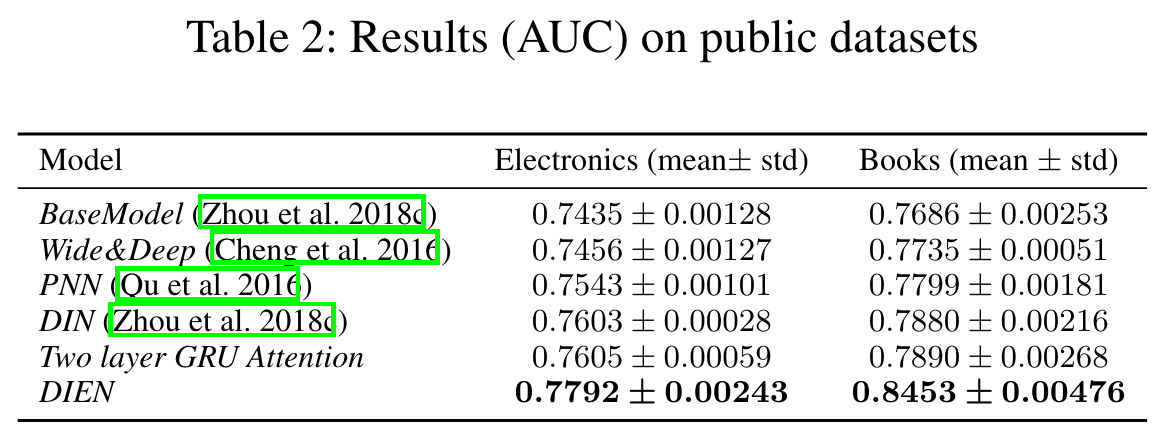
Performance
DIEN
(2018)
to target item, and obtains adaptive interest representation. However, most interest models including DIN regard the behavior as the interest directly, while latent interest is hard to be fully reflected by explicit behavior.
Based on all these observations, we propose Deep Interest Evolution Network (DIEN) to improve the performance of CTR prediction. There are two key modules in DIEN, one is for extracting latent temporal interests from explicit user behaviors, and the other one is for modeling interest evolving process.
We propose auxiliary loss which uses the next behavior to supervise the learning of current hidden state. We call these hidden states with extra supervision as interest states.
We take GRU to model the dependency between behaviors, where the input of GRU is ordered behaviors by their occur time.
We propose auxiliary loss, which uses behavior bt+1 to supervise the learning of interest state ht.
Besides using the real next behavior as positive instance, we also use negative instance that samples from item set except the clicked item.
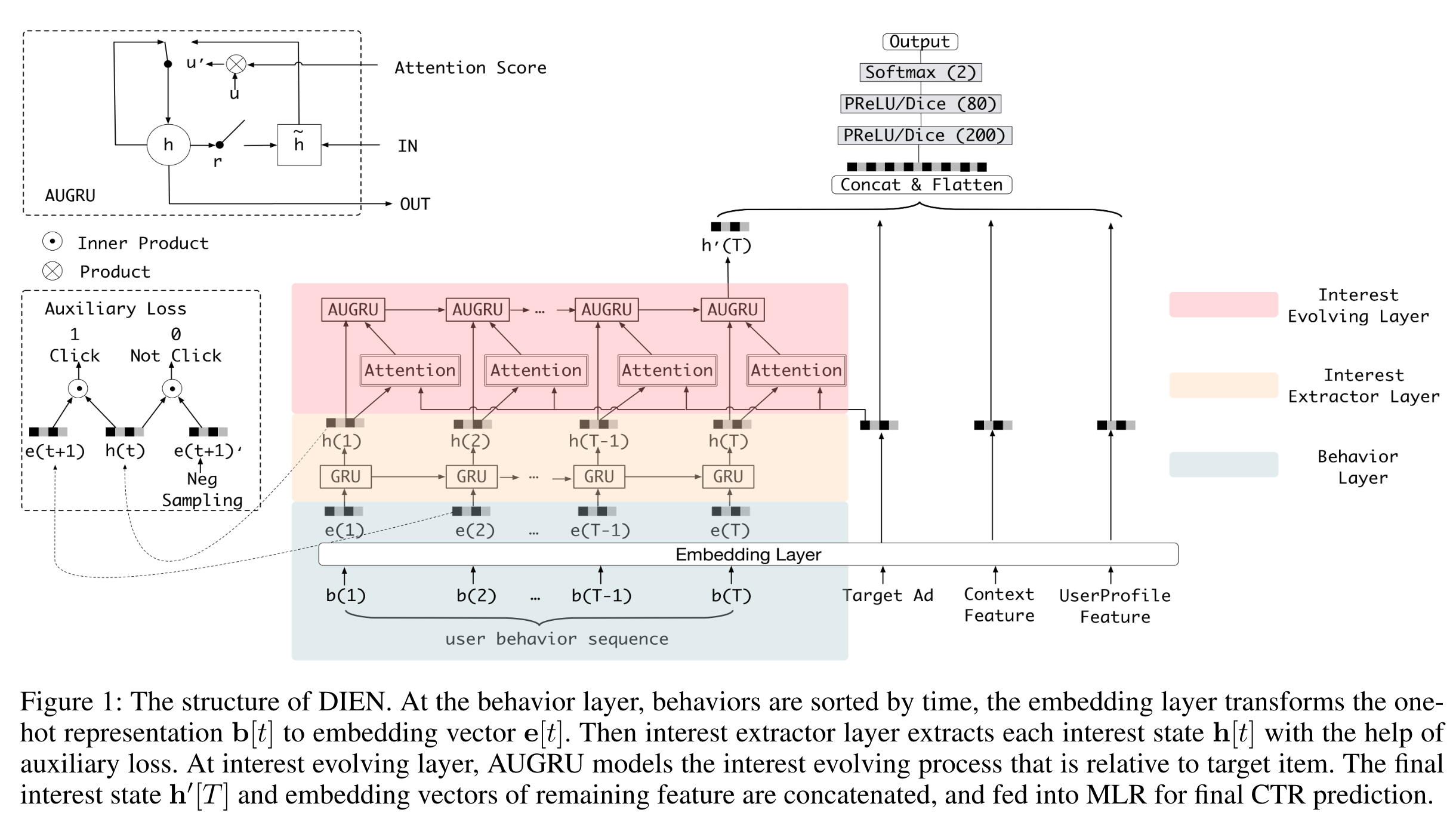
Interest Extractor Layer
The formulations of GRU are listed as follows:
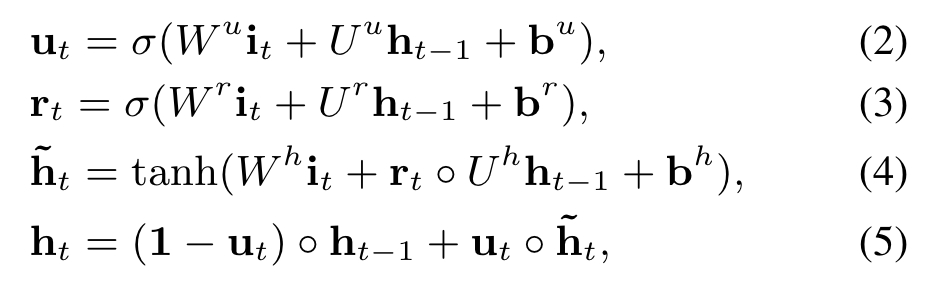
So we propose auxiliary loss, which uses behavior bt+1 to supervise the learning of interest state ht. Besides using the real next behavior as positive instance, we also use negative instance that samples from item set except the clicked item.
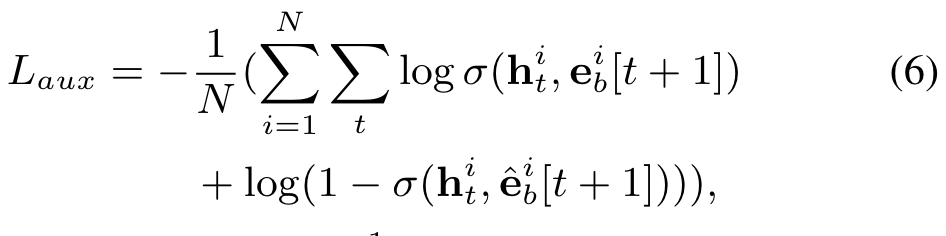
Interest Evolving Layer
GRU with attentional update gate (AUGRU):
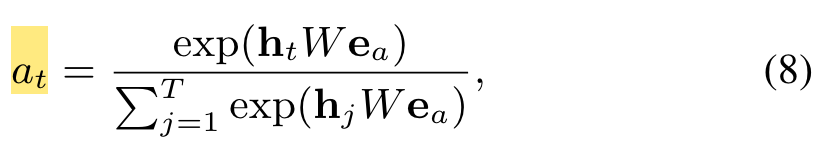
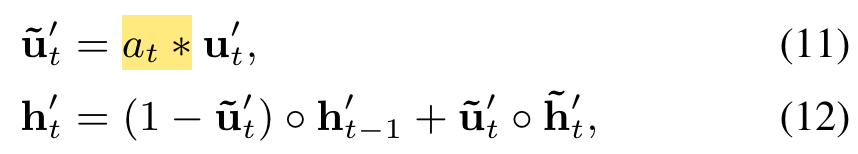
Performance
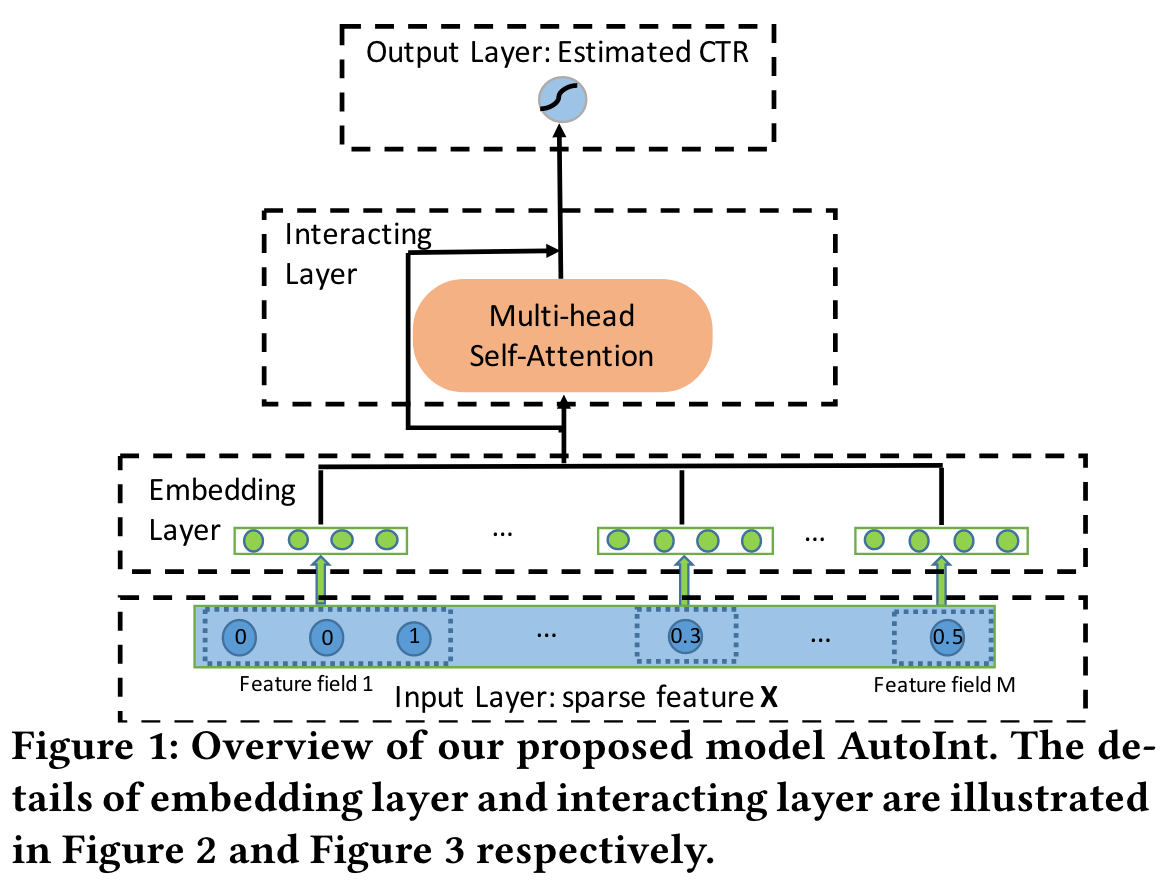
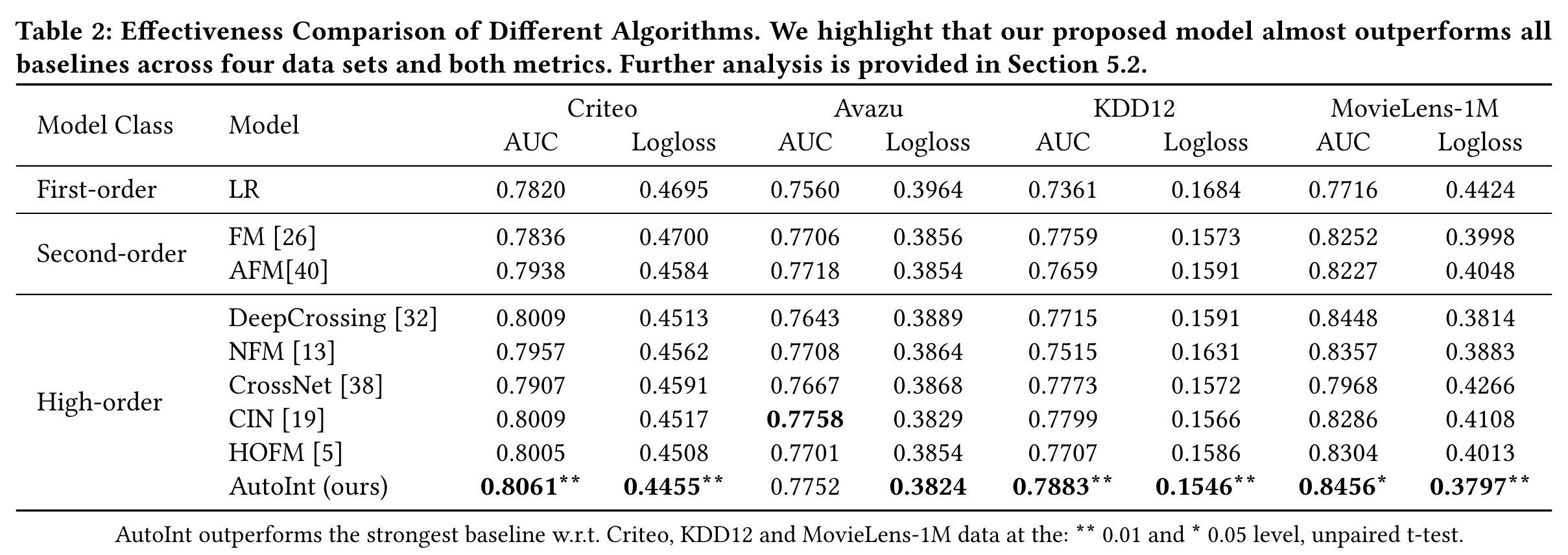
AutoInt
(2019)
In this paper, we propose an effective and efficient method called the AutoInt to automatically learn the high-order feature interactions of input features.
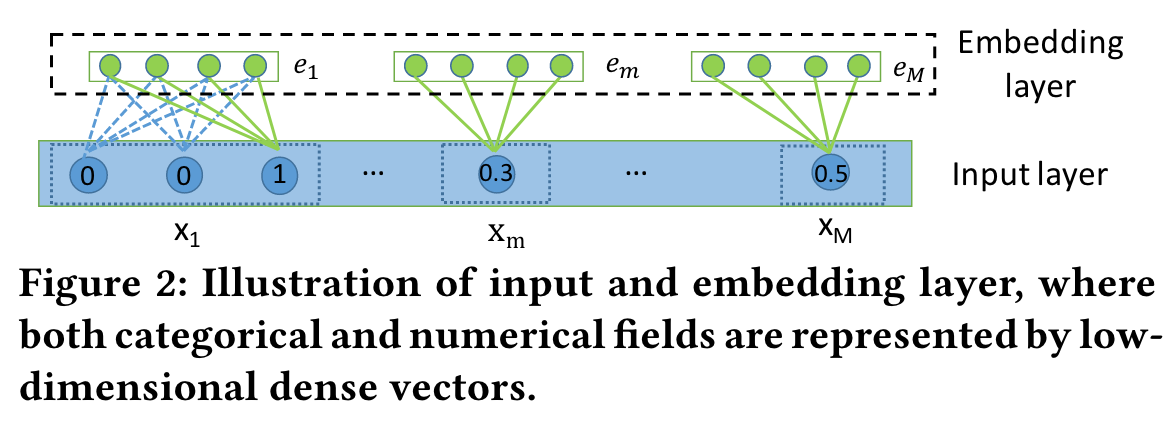
Embedding Layer
Our proposed approach learns effective low-dimensional representations of the sparse and highdimensional input features and is applicable to both the categorical and/or numerical input features.
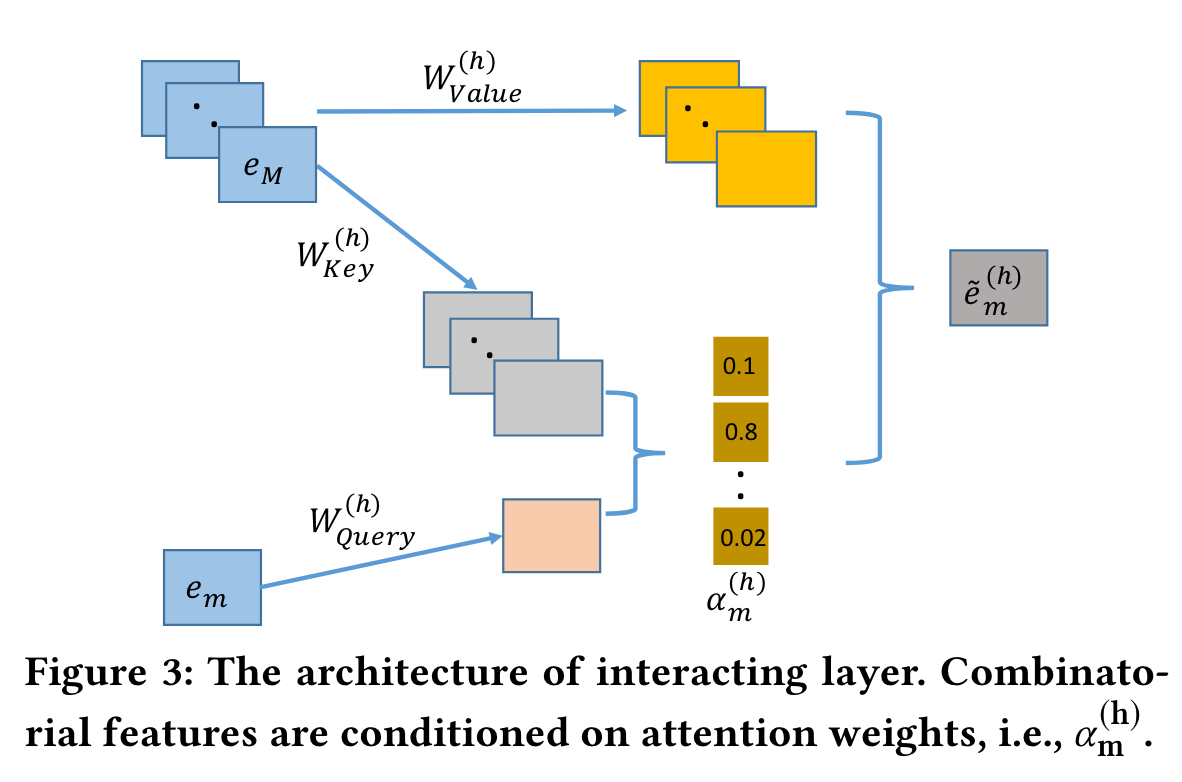
Interacting Layer
We move to model high-order combinatorial features in the space, in this paper, we tackle this problem with a novel method, the multi-head self-attention mechanism.
We first define the correlation between feature m and feature k under a specific attention head h as follows:
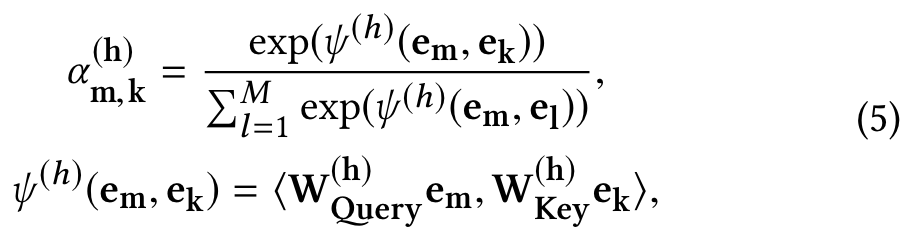
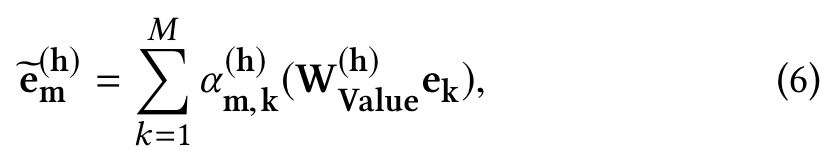
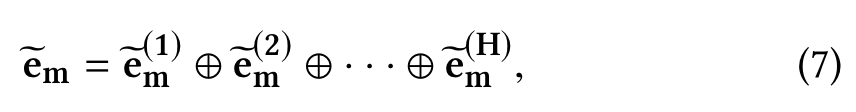
where ψ is an attention function which defines the similarity between the feature m and k, ⊕ is the concatenation operator, and H is the number of total heads.
Performance
DMT
(2020)
We propose Deep Multifaceted Transformers (DMT), a novel framework that can model users’ multiple types of behavior sequences simultaneously with multiple Transformers. It utilizes Multi-gate Mixture-of-Experts to optimize multiple objectives.
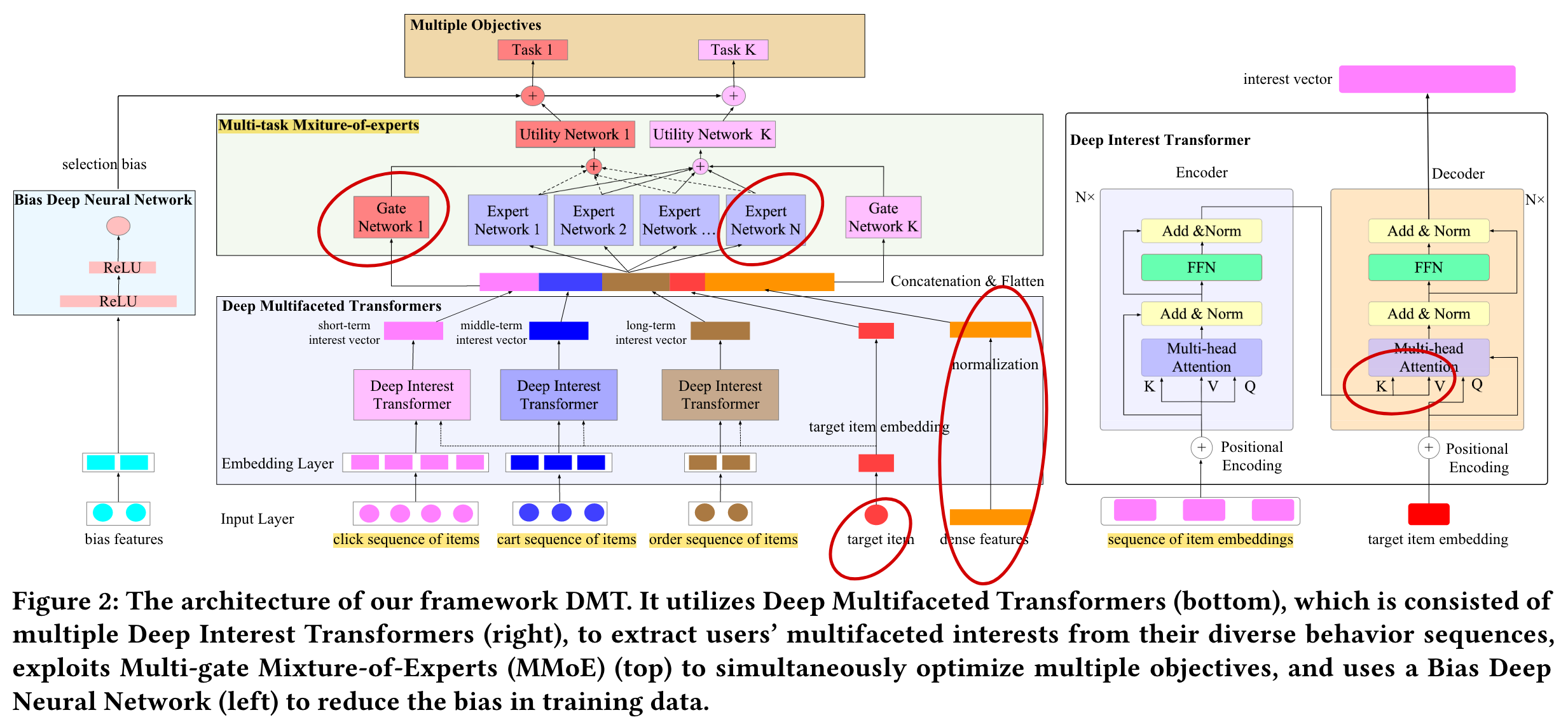
Input and Embedding Layers
Users’ diverse behavior sequences, the sequence of each type of users’ behaviors is represented by a variable-length sequence of items.
Deep Multifaceted Transformers
To capture each user’s multifaceted interest, we use three separate Deep Interest Transformers (they have different parameters) to model the user’s click sequence, cart sequence and order sequence, and learn the user’s short-term, middle-term and long-term interest vectors respectively.
The basic idea is that users’ multiple types of behavior sequences on items (e.g., click, add to cart and order) are significantly difierent and they have different timescales.
Deep Interest Transformer
Self-attention blocks
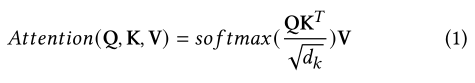

Positional encoding
- Sinusoidal Positional Embedding (pos_sincos)
- Learned Positional Embedding (pos_learn)
Multi-gate Mixture-of-Experts Layers
The multiple objectives may have complex relationships (e.g., independent, related or confiict) with each other, and the commonly used Shared-bottom [23] architecture may harm the learning of multiple objectives. To capture the relation and confiict of multiple tasks, we adopt Multi-gate Mixture-of-Experts (MMoE) [38] for multi-objective ranking.
For each task :, as shown in Equation 3, firstly, it exploits a gating network to learn the weights of each expert. Secondly, it calculates the weighted sum of experts outputs. Finally, it feds into a utility network to get the utility for task. The gating networks and utility networks are implemented by multi-layer perceptrons, and their parameters are different for each task.
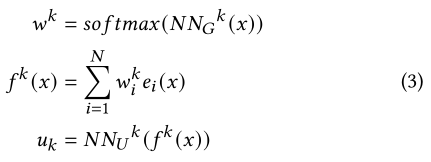
Bias Deep Neural Network
In this paper, we investigate two types of selection bias in e-commerce Recommender Systems: Position bias and Neighboring bias.
- Position bias. The “position bias” means that users tend to click items which are displayed closer to the top of the list.
- Neighboring bias. The “neighboring bias” means that the probability of clicking a item may be influenced by its neighboring products.
DMT uses a Bias Deep Neural Network to model the selection bias. The input of the networks are bias features. For the position bias, the input is the number of index (“Position_index” bias) or page (“Position_page” bias) of the target item. For the neighboring bias, the input is the categories of the target item and its nearest neighboring items.
Performance
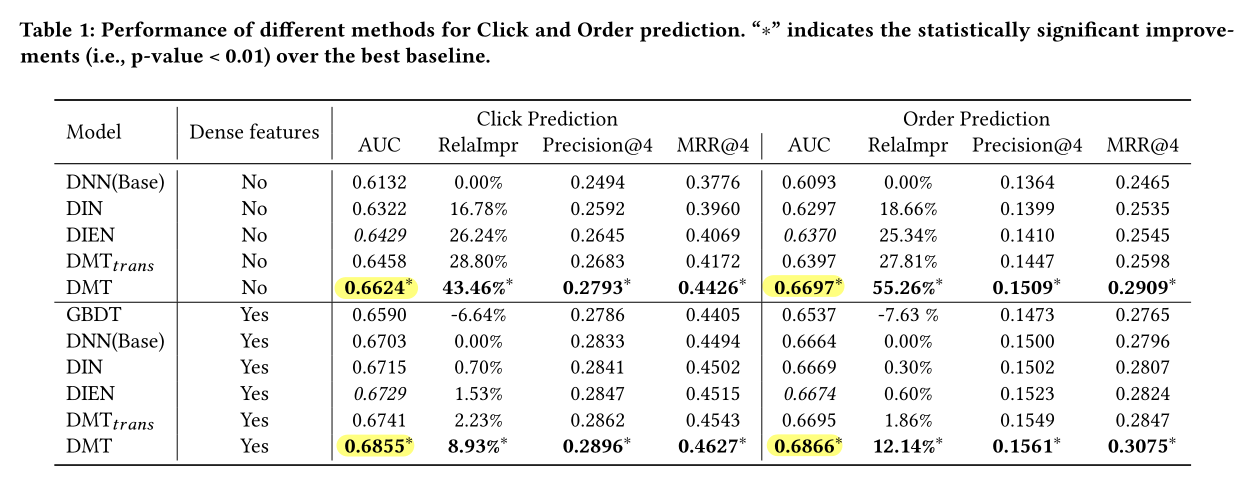
Position bias:
From this table, we can find that: The Learned Positional Embedding method achieves the best performance compared with other methods. So we use this method in the experiments.
MMoE:
we find that simultaneously modeling modeling cart sequence can achieve better performance than singly modeling the click sequence. However, if we further adding the order sequence, the performance for click prediction and order prediction doesn’t increase further.
We empirically find that: For a product that have a long repurchase period (i.e., computer), a user will tend to click but not purchase the product again in short time after buying it. For a product that have a short repurchase period (i.e., milk), the user may both click and purchase it again in short time. The order sequence may lead to the confiict between click prediction and order prediction and disturb the information in the click or cart sequence.
SIM
(2020)
However, MIMN fails to precisely capture user interests given a specific candidate item when the length of user behavior sequence increases further, say, by 10 times or more.
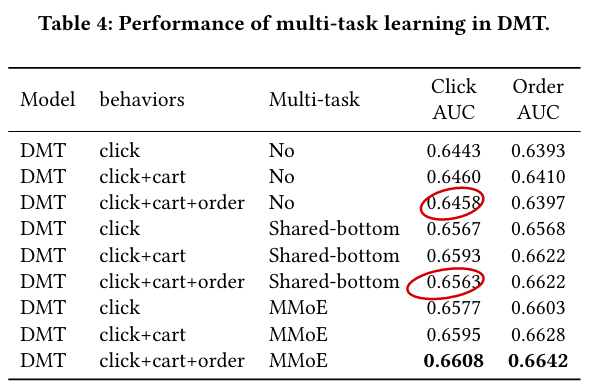
In this paper, we tackle this problem by designing a new modeling paradigm, which we name as Search-based Interest Model (SIM).
Rich user behavior data is proven to be of great value [8]. For example, 23% of users in Taobao, one of the world’s leading e-commerce site, click with more than 1000 products in last 5 months[8, 10]. The key idea of DIN is searching the effective information from user behaviors to model special interest of user, facing different candidate items. But the searching formula of DIN costs an unacceptable computation and storage facing the long sequential user behavior data as we mentioned above.
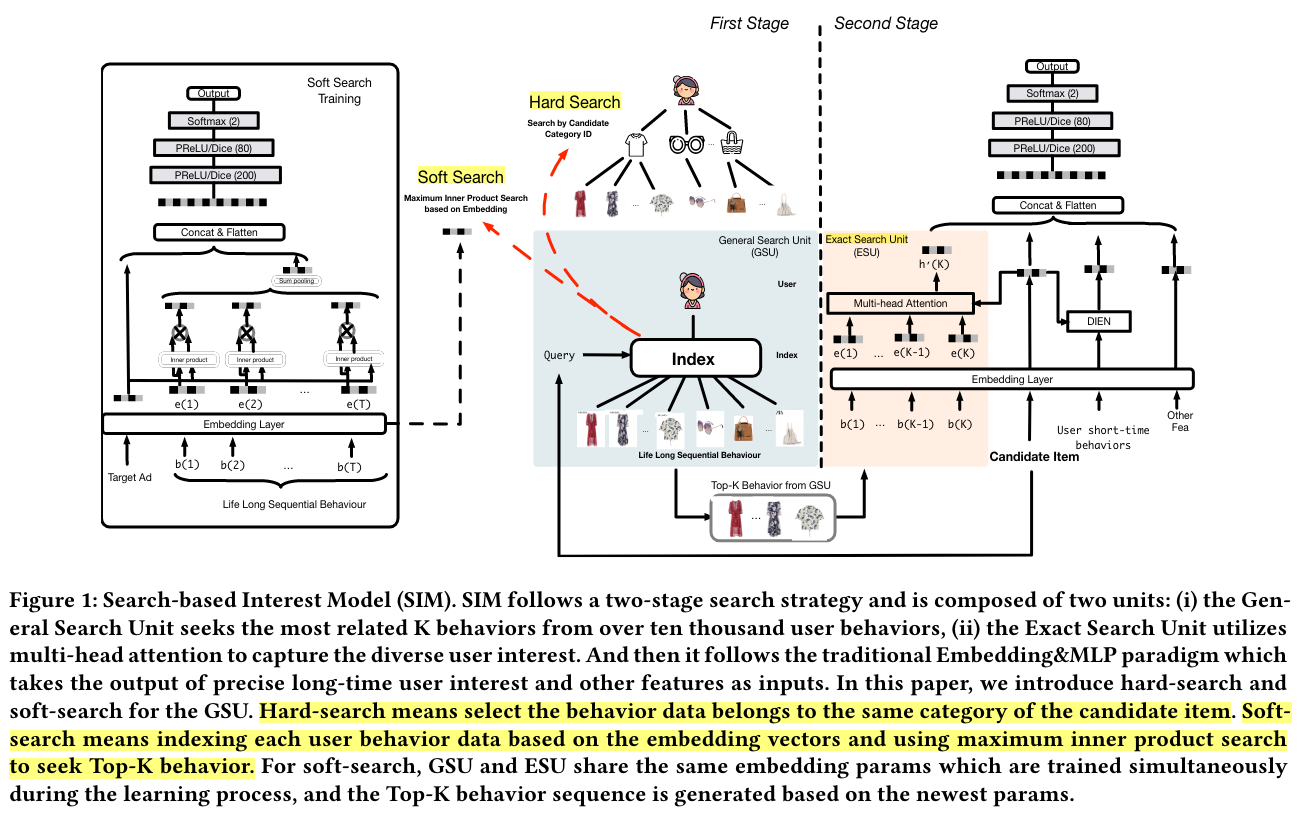
General Search Unit
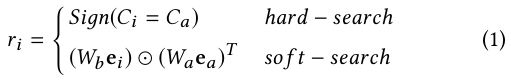
Hard-search:
The hard-search model is non-parametric. Only behavior belongs to the same category as the candidate item will be selected and aggregated as a sub behavior sequence to be sent to the exact search unit.
Soft-search:
In the soft-search model, Wb and Wa are the parameters of weight. ea and ei denote the embedding vectors of target item and i-th behavior bi , respectively.
To further speed up the top-K search over ten thousands length of user behaviors, sublinear time maximum inner product search method ALSH[12] is conducted based on the embedding vectors E to search the related top-K behaviors with target item.
Note that if the user behavior grows to a certain extent, it is impossible to directly fed the whole user behaviors into the model. In that situation, one can randomly sample sets of sub-sequence from the long sequential user behaviors, which still follows the same distribution of the original one.
Exact Search Unit
In the first search stage, top-K related sub user behavior sequence B, and the sequence temporal property for each behavior, specifically, the time intervals D.
We take advantage of multi-head attention to capture the diverse user interest:
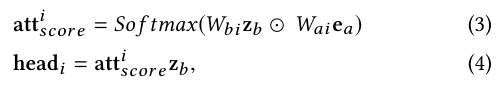
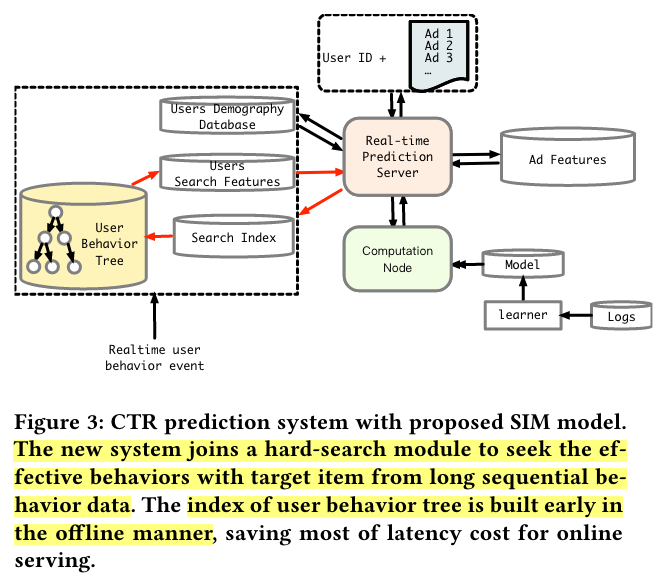
Online Serving System
We build an two-level structured index for each user, which we name as user behavior tree (UBT), as illustrated in Figure 3. Briefly speaking, UBT follows the Key-Key-Value data structure: the first key is user id, the second keys are category ids and the last values are the specific behavior items that belong to each category. UBT is implemented as an distributed system, with size reaching up to 22 TB.
Performance
SIM achieves significant improvement compared with MIMN because MIMN encodes all unfiltered user historical behaviors into a fixed-length memory which makes it hard to capture diverse long-term interest.
The result shows that the user behaviors reserved by hard-search strategy could cover 75% of that from the soft-search strategy.


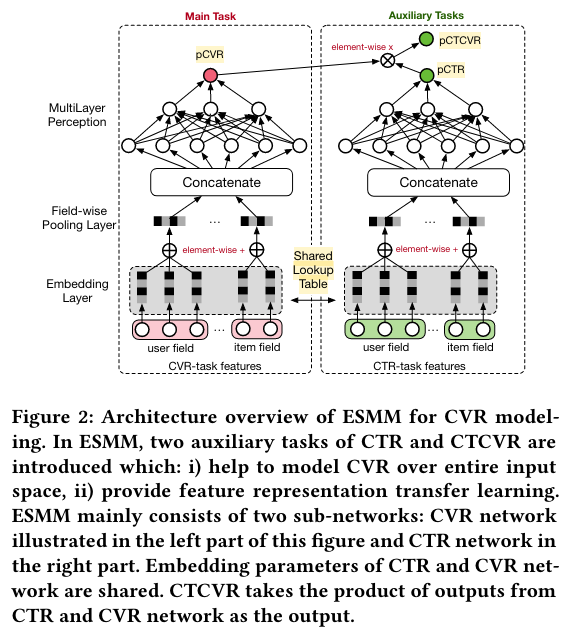
ESMM
(2018)
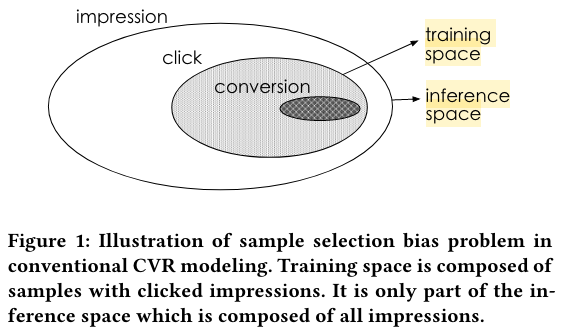
In this paper, we model CVR in a brand-new perspective by making good use of sequential pattern of user actions, i.e., impression → click → conversion. The proposed Entire Space Multi-task Model (ESMM) can eliminate the two problems simultaneously by i) modeling CVR directly over the entire space, ii) employing a feature representation transfer learning strategy.
However, there exist several task-specific problems, making CVR modeling challenging. Among them, we report two critical ones encountered in our real practice:
i) sample selection bias (SSB) problem, As illustrated in Fig.1, conventional CVR models are trained on dataset composed of clicked impressions, while are utilized to make inference on the entire space with samples of all impressions.
ii) data sparsity (DS) problem, In practice, data gathered for training CVR model is generally much less than CTR task.
CVR Modeling
Eq.(2) tells us that with estimation of pCTCVR and pCTR, pCVR can be derived over the entire input space X, which addresses the sample selection bias problem directly.
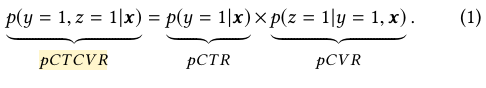
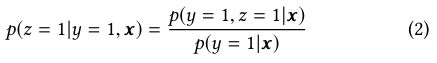
Entire Space Multi-Task Model
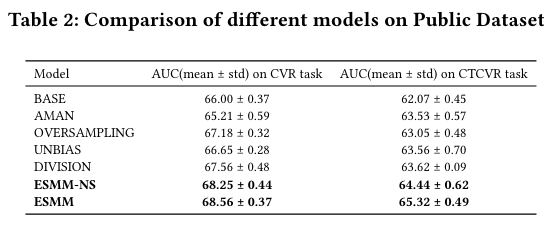
Performance
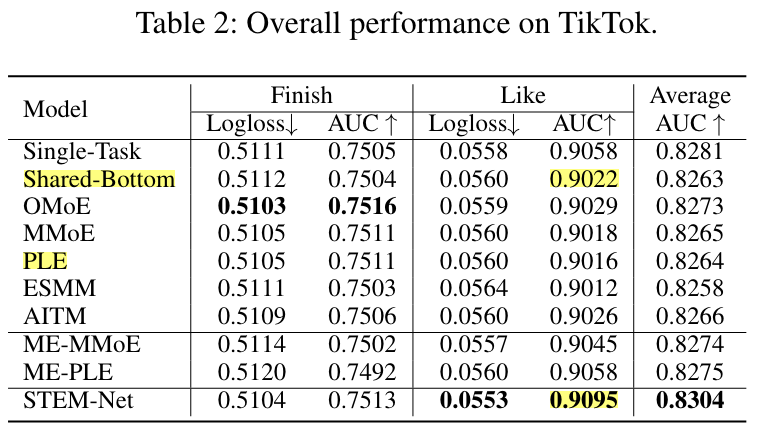
STEM
(2018)
In this paper, we introduce a novel paradigm called Shared and Task-specific EMbeddings (STEM) that aims to incorporate both shared and task-specific embeddings to effectively capture task-specific user preferences.
A key challenge in MTL is the occurrence of negative transfer, where the performance of certain tasks deteriorates due to conflicts between tasks.
Note that, existing methods tend to treat all samples in a task as a whole, overlooking the inherent intricacies within them.
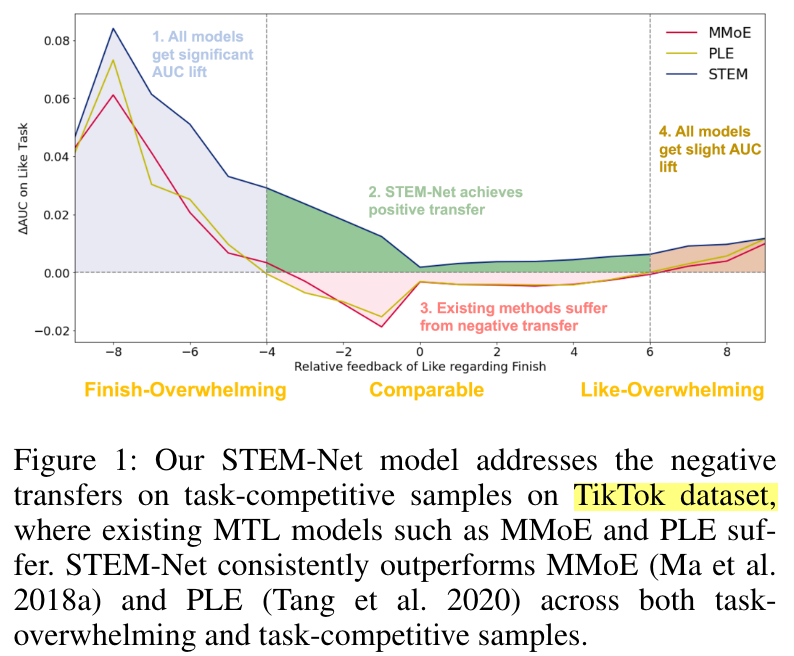
However, to our surprise, in the zone that receives comparable positive feedback from both tasks, the performance of existing methods is inferior to that of the single-task model.
Intuitively, users may possess diverse and sometimes even conflicting preferences for items across various tasks, which become more pronounced when there are sufficient signals from multiple tasks, as in the comparable zone here.
Motivated by the limitations of the shared-embedding paradigm, this paper introduces a Shared and Task-specific EMbeddings (STEM) paradigm. STEM aims to incorporate both shared and task-specific embeddings to learn taskspecific user preferences.
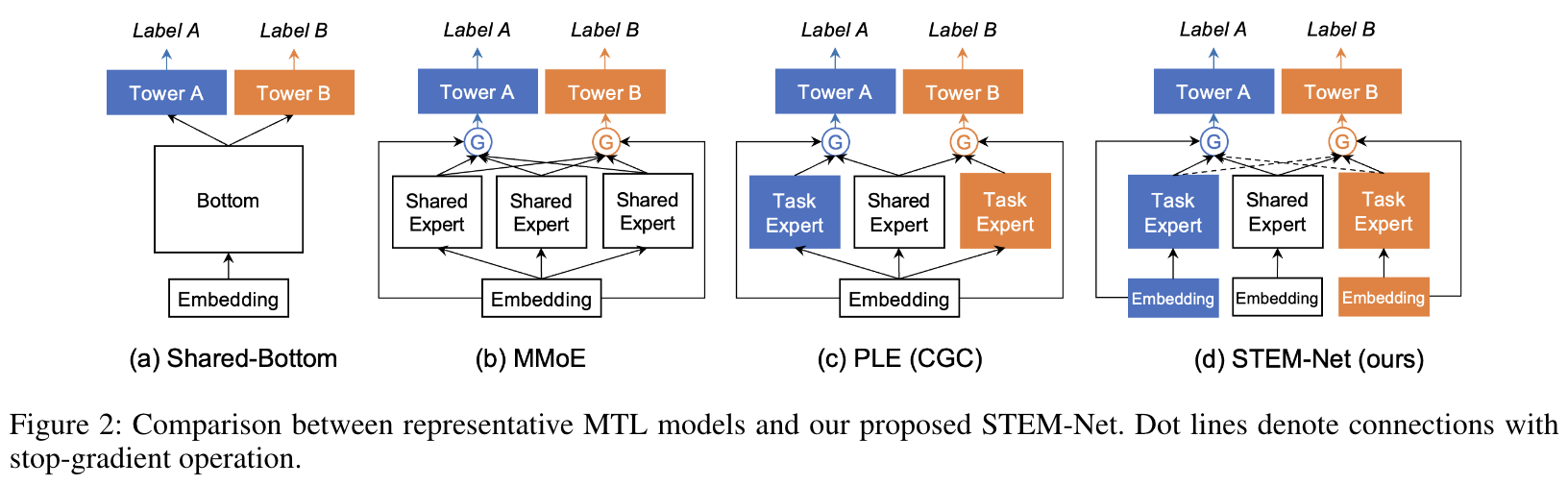
Evolution of the MTL Model Architectures
As depicted in Figure 1, both MMoE and PLE demonstrate improved performance when there is overwhelming feedback from either task.
STEM-Net
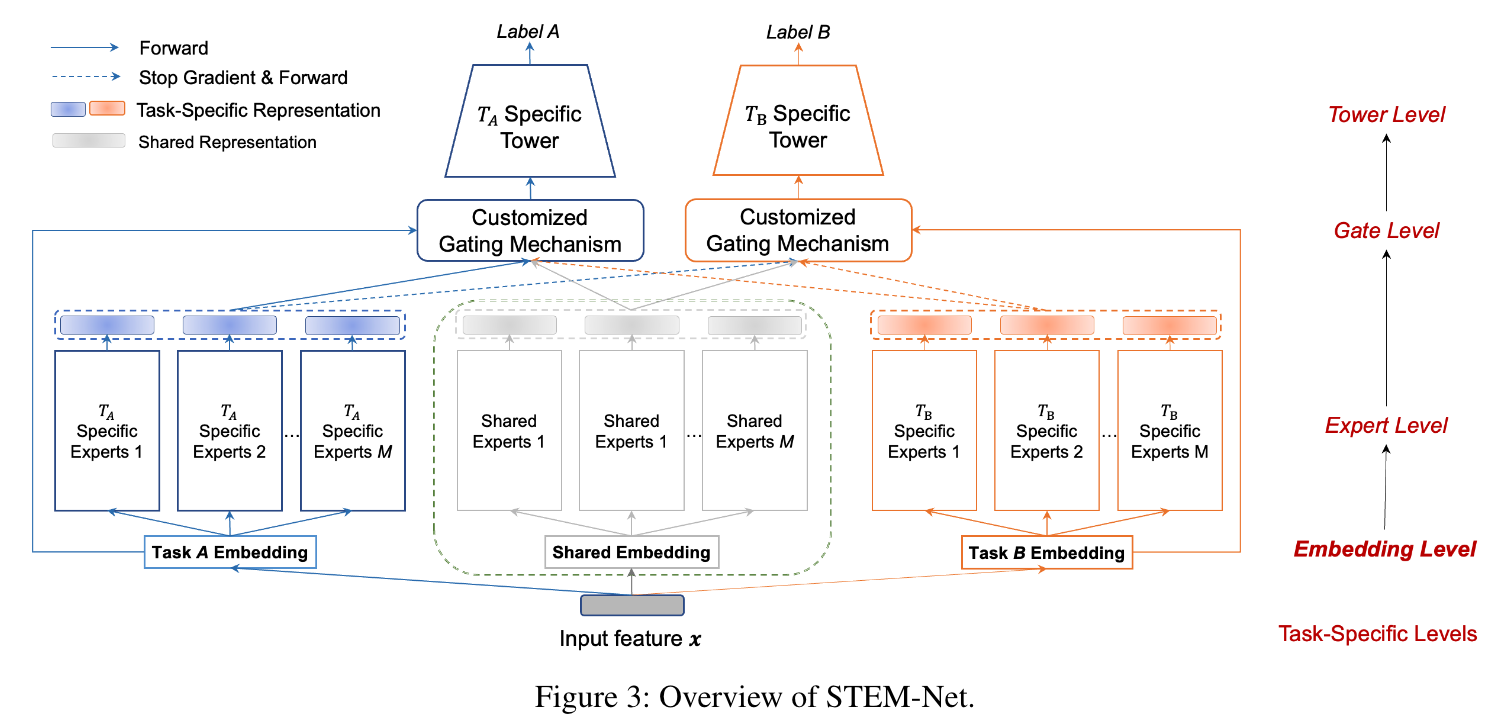
USER ID and ITEM ID task-specific
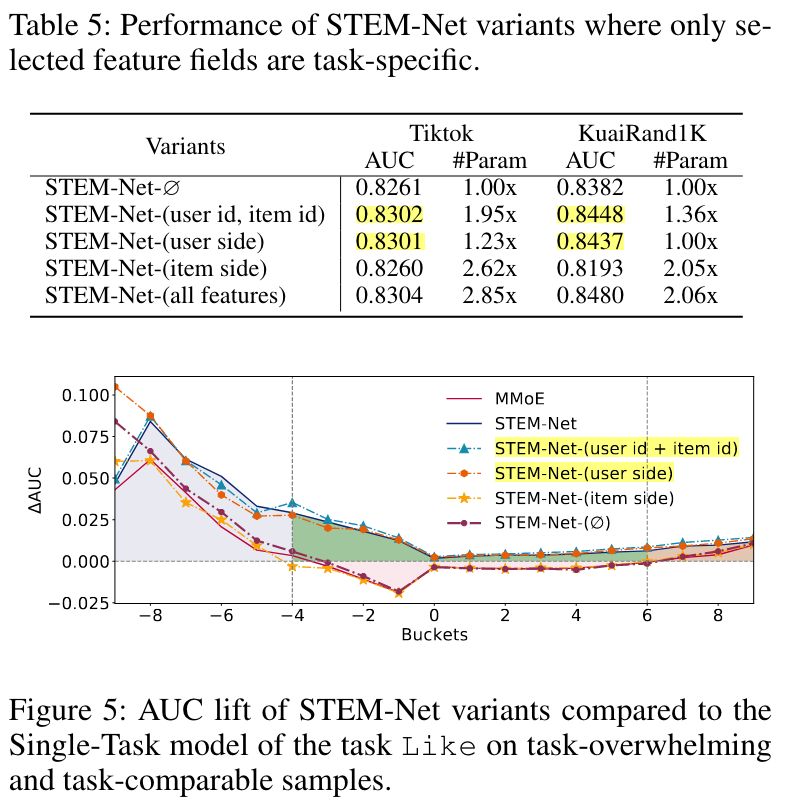
We wonder if we can still achieve decent performance lift when only making embeddings of USER ID and ITEM ID task-specific. We evaluate the performance of the corresponding model STEM-Net-(user id, item id) observing that it also achieves competitive performance with STEM-Net.
We design two new variants, STEM-Net-(user side) and STEM-Net-(item side), and observe the former one exhibit better performance, indicating that user side features are more effective than item in capturing diverse user preference among tasks.
Performance
EDCN
(2021)
We propose a novel deep CTR model EDCN. EDCN introduces two advanced modules, namely bridge module and regulation module, which work collaboratively to capture the layer-wise interactive signals and learn discriminative feature distributions for each hidden layer of the parallel networks.
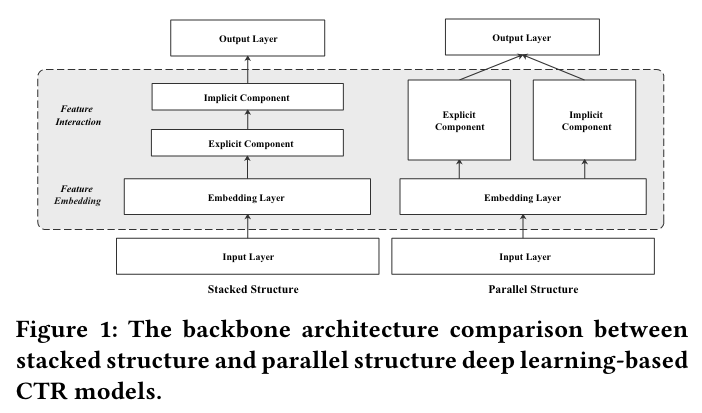
In this paper, we focus on optimizing the models with parallel structure by enhancing the explicit and implicit feature interactions via information sharing.
Insufficient sharing in hidden layers
We refer such fusion pattern(DCN) as late fusion. With late fusion, explicit and implicit feature interaction networks do not share information in the intermediate hidden layers, which weakens the interactive signals between each other and may easily lead to skewed gradients during the backward propagation.
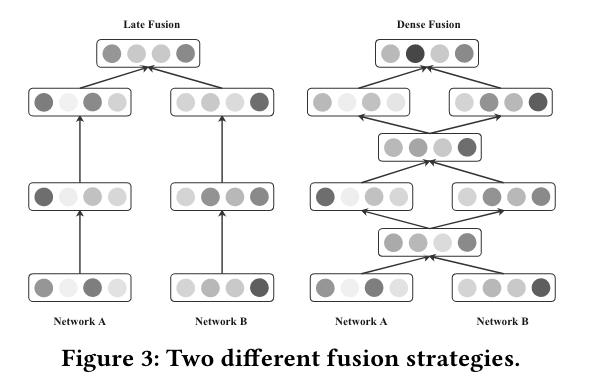
Excessive sharing in network input
Therefore, excessive sharing the network inputs and feeding all the features indiscriminately to the parallel networks may not be a reasonable choice and result in sub-optimal performance.
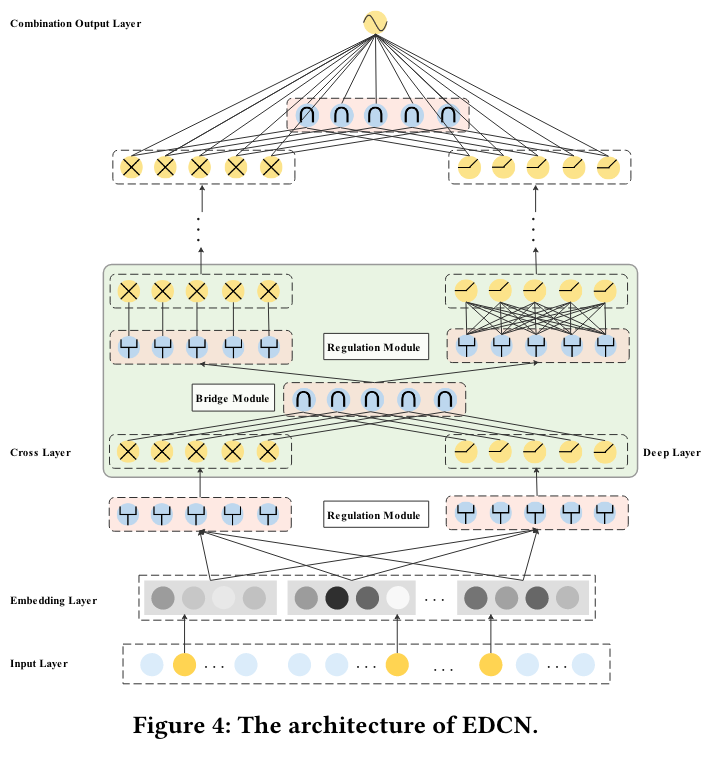
Bridge Module
To overcome this limitation, we introduce a dense fusion strategy, which is implemented by our proposed bridge module, to capture the layer-wise interactive signals between two parallel networks.
the bridge module can be formulated as f𝑙 = 𝑓 (x𝑙 , h𝑙 ), where 𝑓 (·) is a pre-defined interaction function:
- Pointwise Addition
- Hadamard Product
- Concatenation
- Attention Pooling
Regulation Module
(SE-Net) Inspired by the gating mechanism used in MMoE [20], we propose a regulation module, implemented by a field-wise gating network to soft-select discriminative feature distributions for each parallel networks.
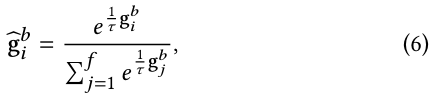
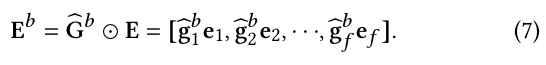
Performance
STAR
(2021)
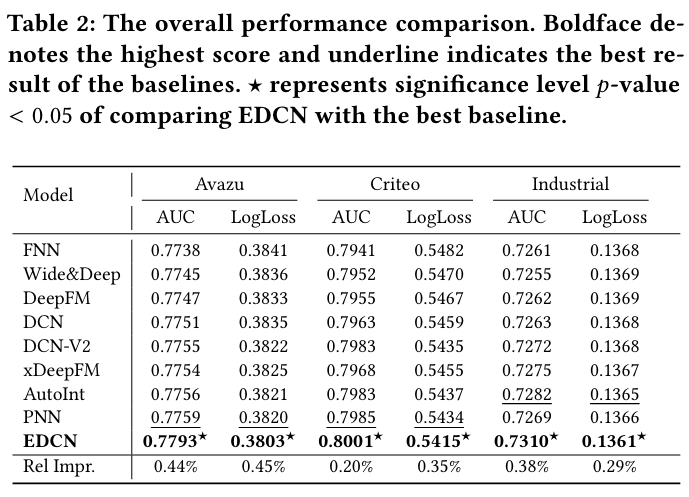
Generally, different domains may share some common user groups and items, and each domain may have its own unique user groups and items.
In this paper, we propose the Star Topology Adaptive Recommender (STAR) model to train a single model to serve all domains by leveraging data from all domains simultaneously, capturing the characteristics of each domain, and modeling the commonalities between different domains.
Architecture Overview
We propose Star Topology Adaptive Recommender (STAR) for multi-domain CTR prediction to better utilize the similarity among different domains while capturing the domain distinction.
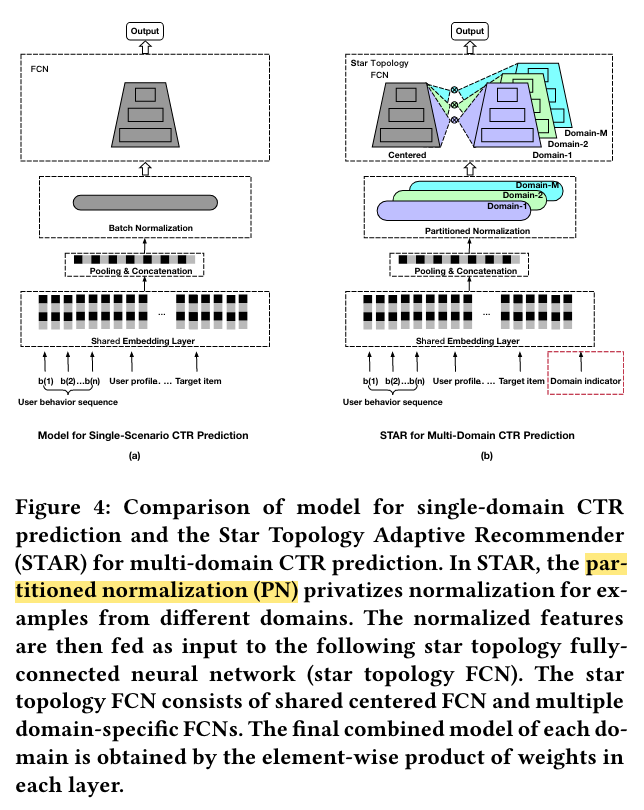
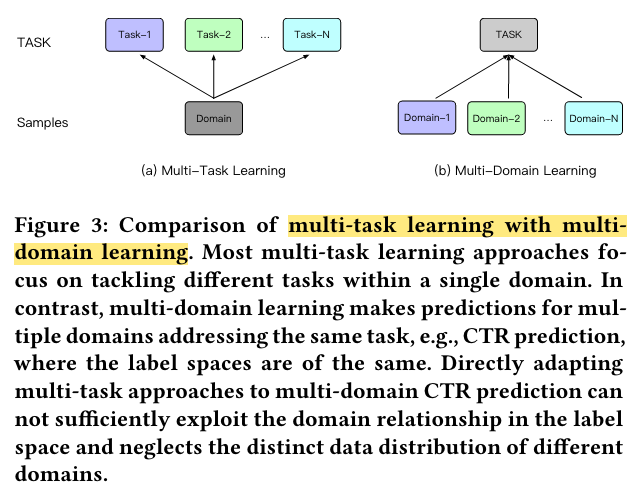
As shown in Figure 4, STAR consists of three main components:
(1) the partitioned normalization (PN) which privatizes normalization for examples from different domains,
(2) the star topology fully-connected neural network (star topology FCN),
(3) the auxiliary network that treats the domain indicator directly as the input feature and learns its semantic embeddings to capture the domain distinction.
Partitioned Normalization
Among all normalization methods, batch normalization (BN) [14] is a representative method that is proved to be crucial to the successful training of very deep neural networks [14, 31].
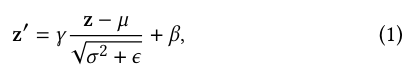
During testing, moving averaged statistics of mean 𝐸 and variance 𝑉 𝑎𝑟 across all samples are used instead
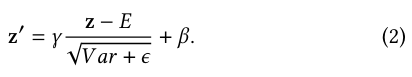
To capture the unique data characteristic of each domain, we propose partitioned normalization (PN) which privatizes normalization statistics and parameters for different domains.
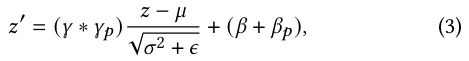
Besides the modification of the scale and bias, PN also let different domains to accumulate the domain-specific moving average of mean 𝐸𝑝 and variance 𝑉 𝑎𝑟𝑝
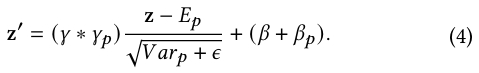
Star Topology FCN
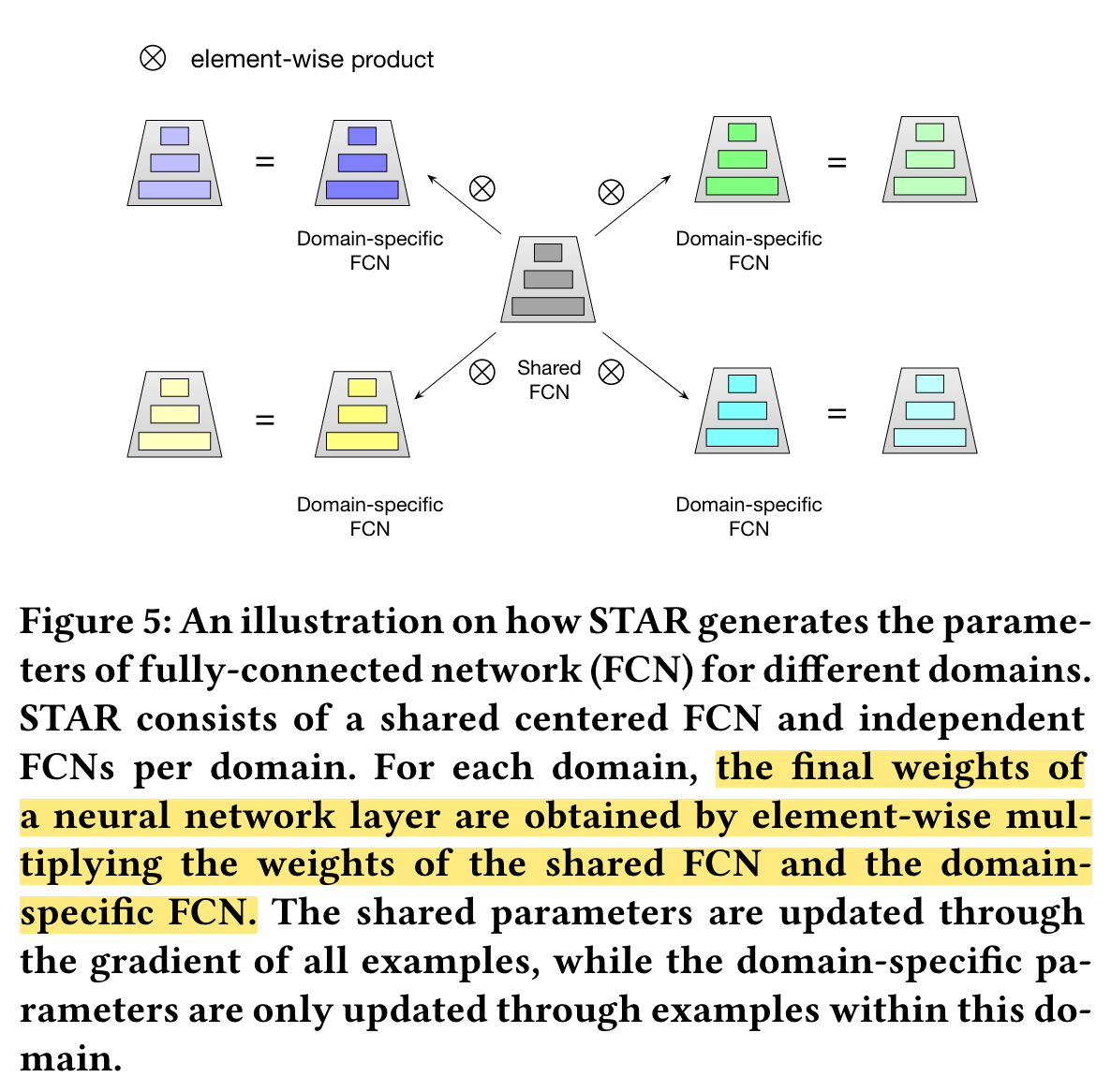
As depicted in Figure 5, the proposed star topology FCN consists of a shared centered FCN and independent FCNs per domain, thus the total number of FCN is 𝑀 + 1.
The final model of 𝑝-th domain is obtained by combining the shared centered FCN and domain-specific FCN, in which the centered parameters learn general behaviors among all domains, and the domain-specific parameters capture specific behaviors in different domains to facilitate more refined CTR prediction.
The final weights 𝑊 ★ 𝑖 and bias 𝑏★ 𝑖 for the 𝑝-th domain is obtained by:
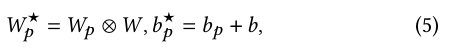
Auxiliary Network
We argue that a good multi-domain CTR model should have the following characteristic: (1) have informative features regarding the domain characteristic (2) make these features easily and directly influence the final CTR prediction.
To this end, we propose an auxiliary network to learn the domain distinction. To augment informative features regarding the domain characteristic, we treat the domain indicator directly as the ID feature input.
The domain indicator is first mapped into embedding vector and concatenated with other features. The auxiliary network then computes forward pass with respect to the concatenated features to gets the one-dimensional output 𝑠𝑎.
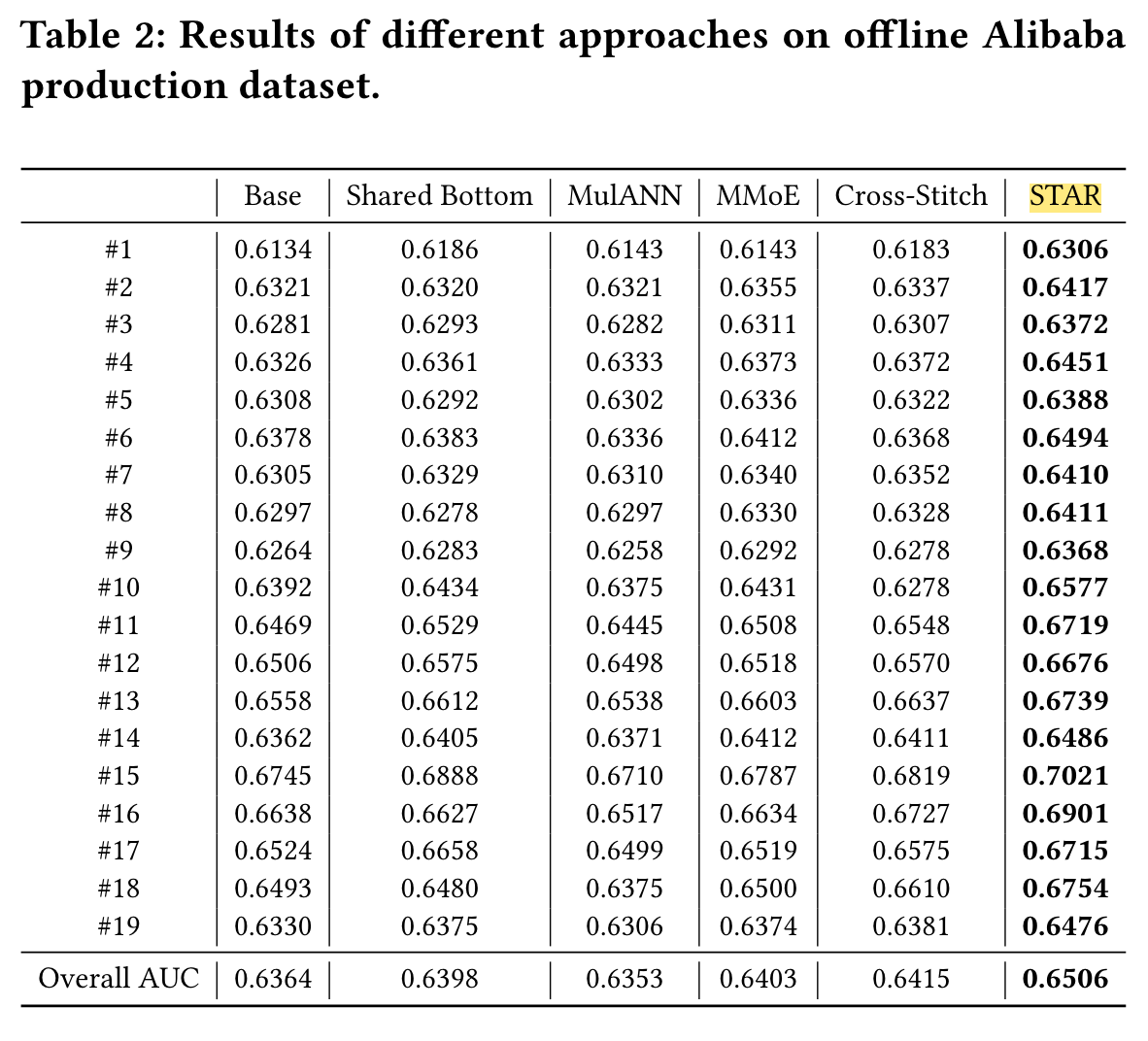
Performance
AutoGroup
(2020)
An end-to-end model, AutoGroup, is proposed, which casts the selection of feature interactions as a structural optimization problem.
The main contribution of AutoGroup is that it performs both dimensionality reduction and feature selection which are not seen in previous models.
In real-world scenarios, useful feature interactions are usually sparse relative to the combination space of raw features
Modelling with AutoGroup consists of three stages:
- the Automatic Feature Grouping Stage,
- the Interaction Stage,
- and the MLP Stage.
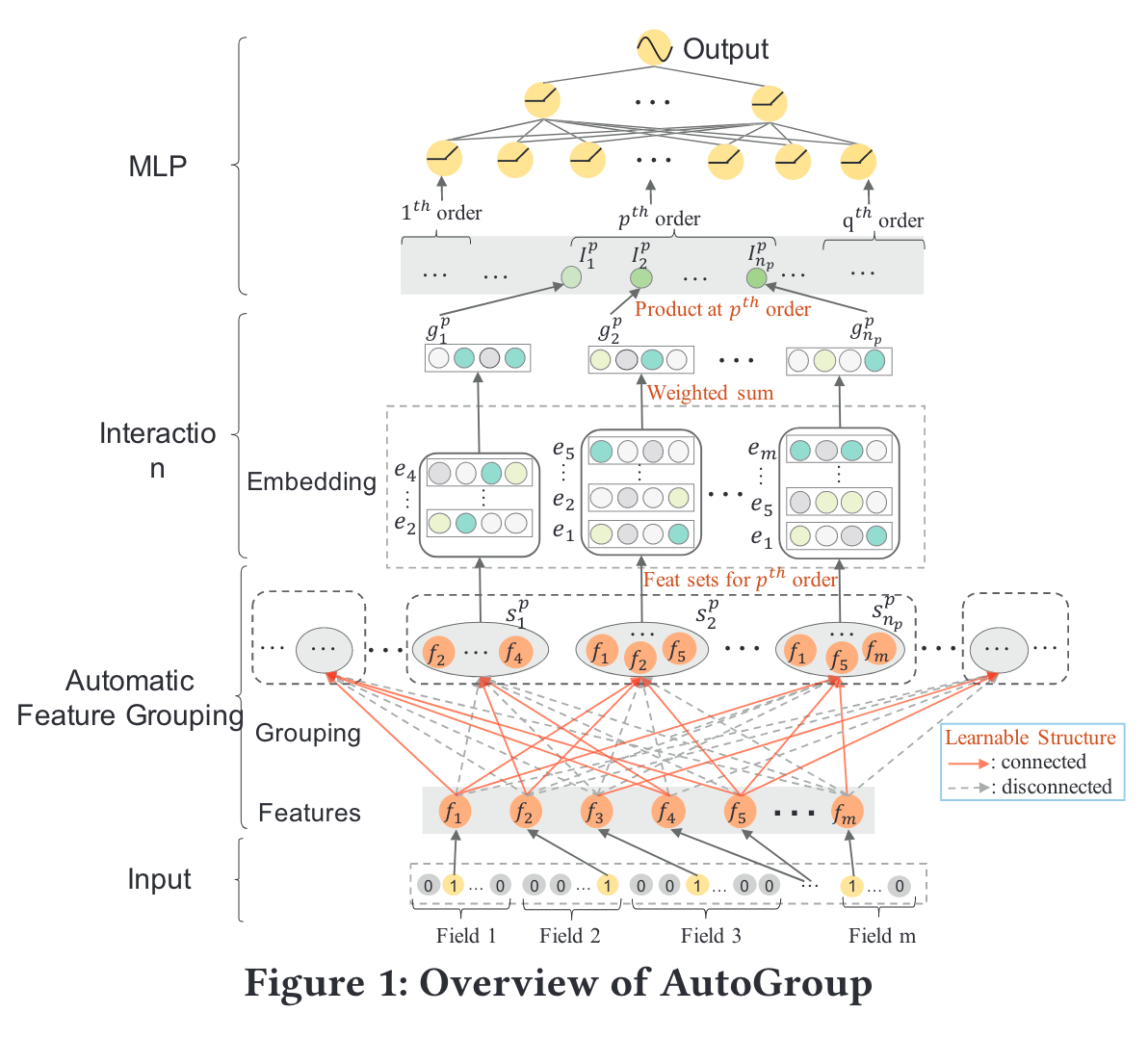
Automatic Feature Grouping Stage
The simple strategy of enumerating all feature interactions makes neural networks difficult to achieve the optimal set of network weights.
The main idea is to find multiple small sets of features, where the feature interactions in each such identified feature set are effective at a given order.
As shown in Figure 1, the selection of feature sets can be viewed as a structural optimization problem: each feature is allowed to be selected by any feature set where each feature set groups related features together such that their interaction is likely to improve prediction performance.
We relax the binary choice of a feature being selected by a feature set to a softmax over the two possibilities:
(to indicate whether feature fi is selected into feature set
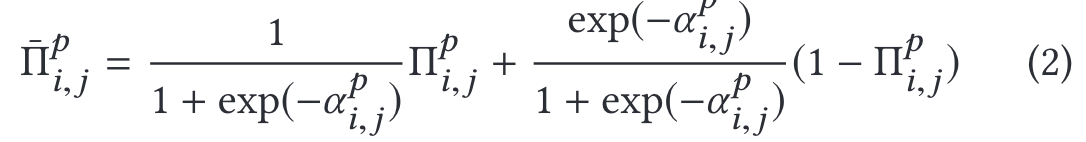
To make the operation differentiable, we relax it with a softmax:
Interaction Stage
Specifically, the representation of a feature set is the weighted sum of representations of the features in this set.

In this paper, we generalize the reformulation (Eq. 7) for the pth-order interaction as:
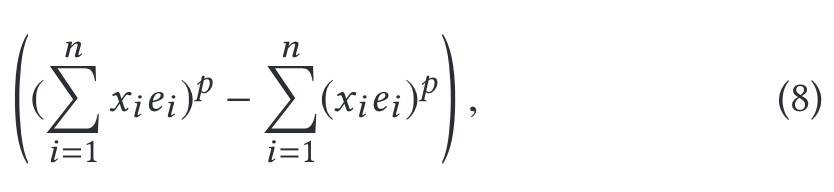
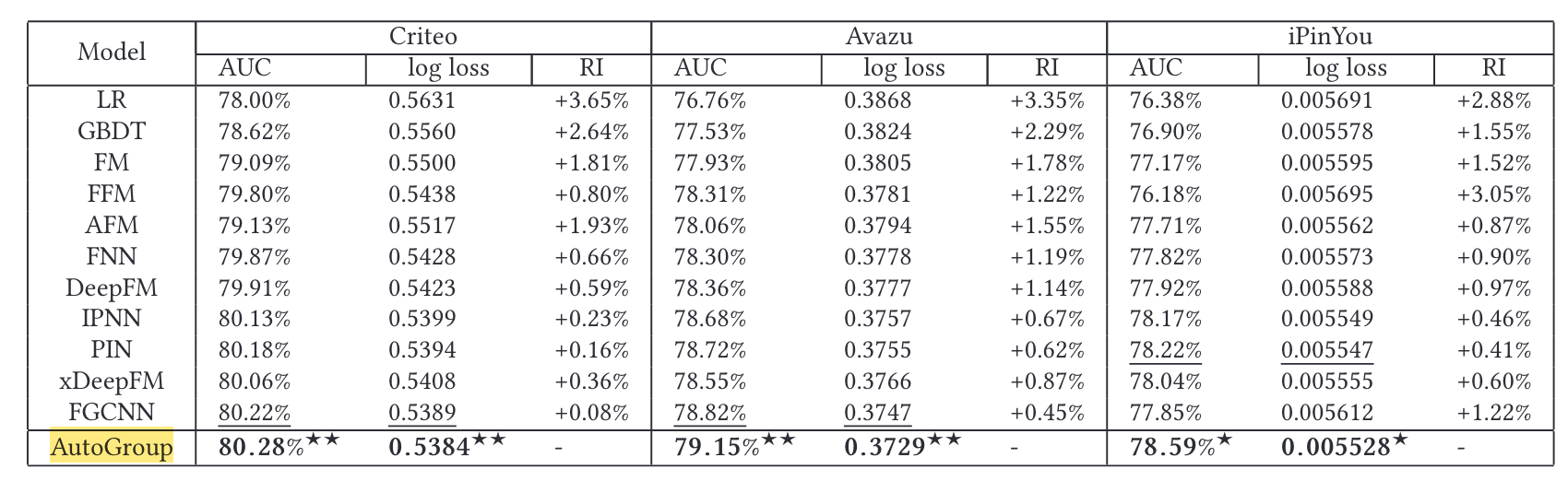
Performance
CD2AN
(2022)
From the popularity distribution shift perspective, the normal paradigm trained on exposed items (most are hot items) identifies that recommending popular items more frequently can achieve lower loss, thus injecting popularity information into item property embedding.
Existing work addresses this issue with inverse propensity scoring (IPS) or causal embeddings.
However, we argue that not all popularity biases mean bad effects, We propose a co-training disentangled domain adaptation network (CD2AN), which can co-train both biased and unbiased models.
Specifically, for popularity distribution shift, CD2AN disentangles item property representation and popularity representation from item property embedding.
For long-tail distribution shift, we introduce additional unexposed items (most are long-tail items) to align the distribution of hot and long-tail item property representations.
Further, from the instances perspective, we carefully design the item similarity regularization to learn comprehensive item representation, which encourages item pairs with more effective co-occurrences patterns to have more similar item property representations.
Existing work eliminates this bias effect with inverse propensity scoring (IPS) or causal embeddings.
(1) IPS, which employs balanced training by re-weighting the interactions [14, 33].
(2) Causal embeddings, which formulate a causal graph to describe the important cause-effect relations in the recommendation process.
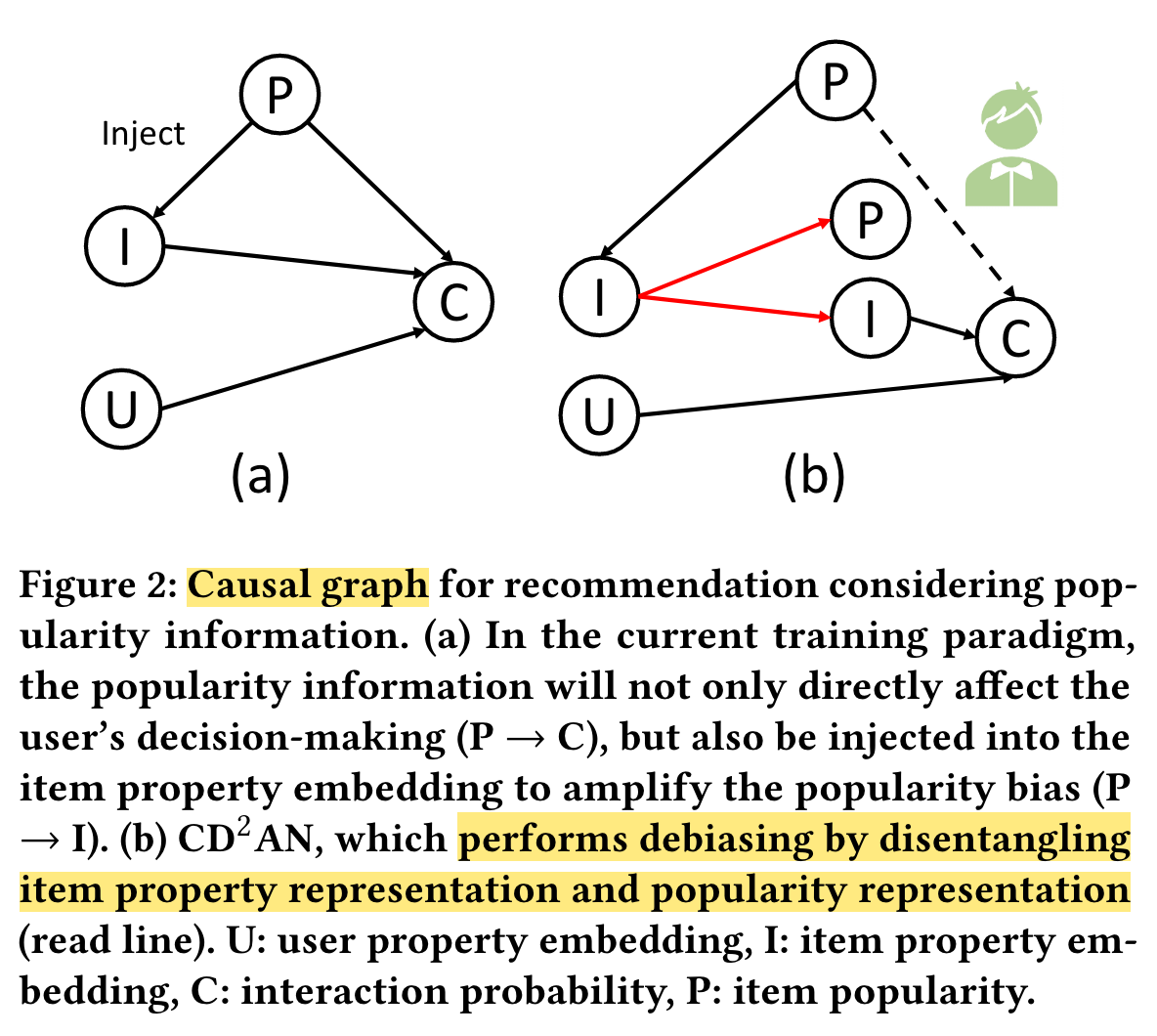
The key challenge is how to alleviate popularity and long-tail distribution shifts to obtain an unbiased and comprehensive item representations.
We design a feature disentangling module with orthogonal regularization and popularity similarity regularization to separate the popularity representation and the item property representation from the item property embedding injected with the popularity information.
Feature Disentangling Module
Based on this training paradigm, there are two main reasons for the popularity bias. (1) Popularity information is injected into the item property embedding, which increases the vector length of popular items, making inner product models score popular items high for every user [41]. (2) Data sparsity makes long-tail items unable to obtain good representations,
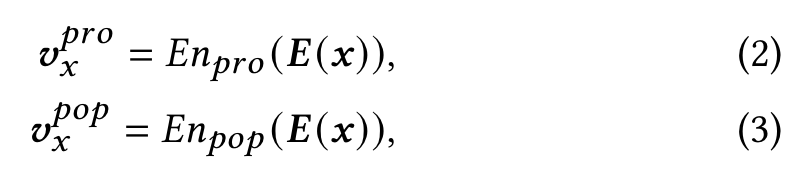
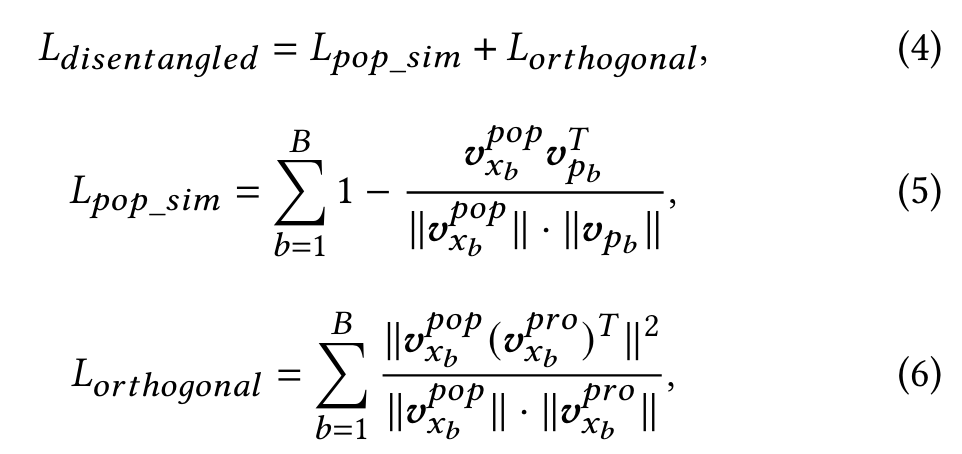
𝐿𝑝𝑜𝑝_𝑠𝑖𝑚 encourages the module to separate out the popularity information injected into 𝑬 (𝑥) by constraining 𝒗𝑝𝑜𝑝 𝑥 to be similar to 𝒗𝑝
𝐿𝑜𝑟𝑡ℎ𝑜𝑔𝑜𝑛𝑎𝑙 encourages orthogonality between 𝒗𝑝𝑜𝑝 𝑥 and 𝒗𝑝𝑟𝑜 𝑥 , enabling the popularity and property encoders to encode different aspects of the inputs.
Regularizations for Long-tail Shift
Domain Alignment
Although item property representations 𝒗𝑝𝑟𝑜 𝑥 are extracted through FDM, we believe that the popularity bias still exists due to data sparsity. Compared with popular items with sufficient interaction, long-tail items cannot be effectively learned.
Inspired by domain adaptation, we additionally introduce unexposed items 𝑥𝑘 (most are long-tail items) randomly sampled from the entire item pool, and adopt Maximum Mean Discrepancy (MMD) regularization [13] to align the distribution of hot and long-tail items:
Instance Alignment
Intuitively, 𝐿𝑀𝑀𝐷 encourages the cluster center of long-tail items to approach the cluster center of hot items.
In the training stage, we additionally introduce the user’s historical interacted items in the item tower. Based on contrastive learning [7, 38], we encourage the items clicked by the same user to be more similar.
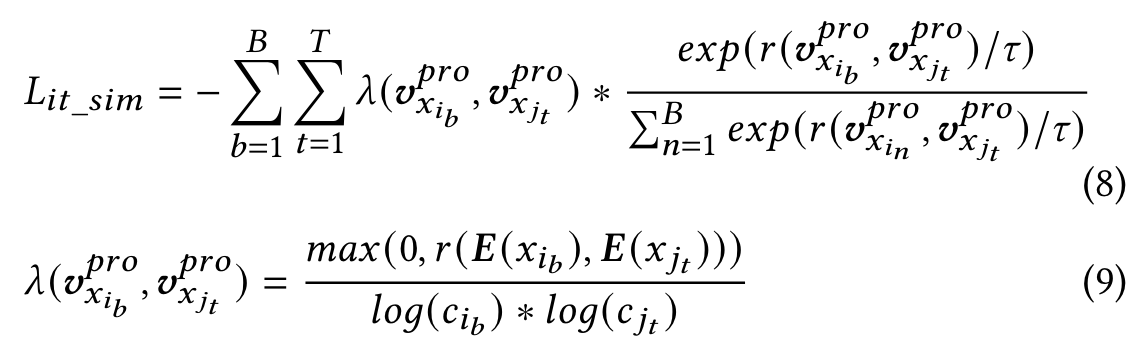
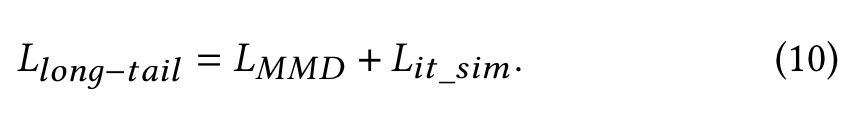
Co-training
However, we argue that not all popularity biases mean bad effects. The reason why an item is popular maybe that it is of good quality or in line with the current trend.
we co-train unbiased model and biased model to optimize top-k accuracy by adopting the batch softmax loss used in both recommenders [39] and NLP [12]:
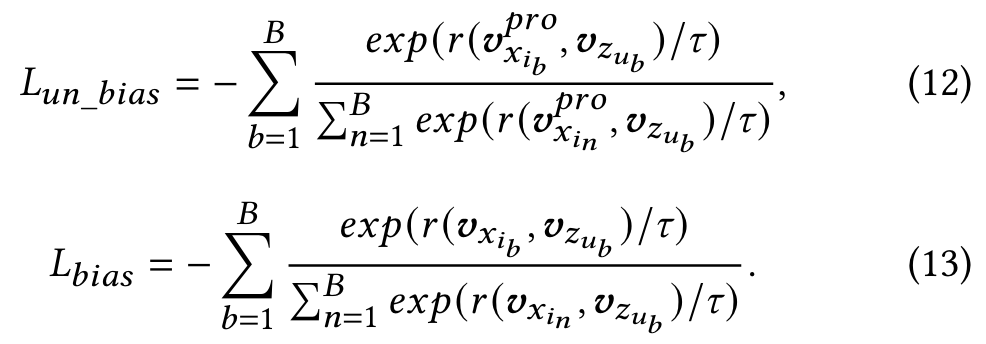
Performance
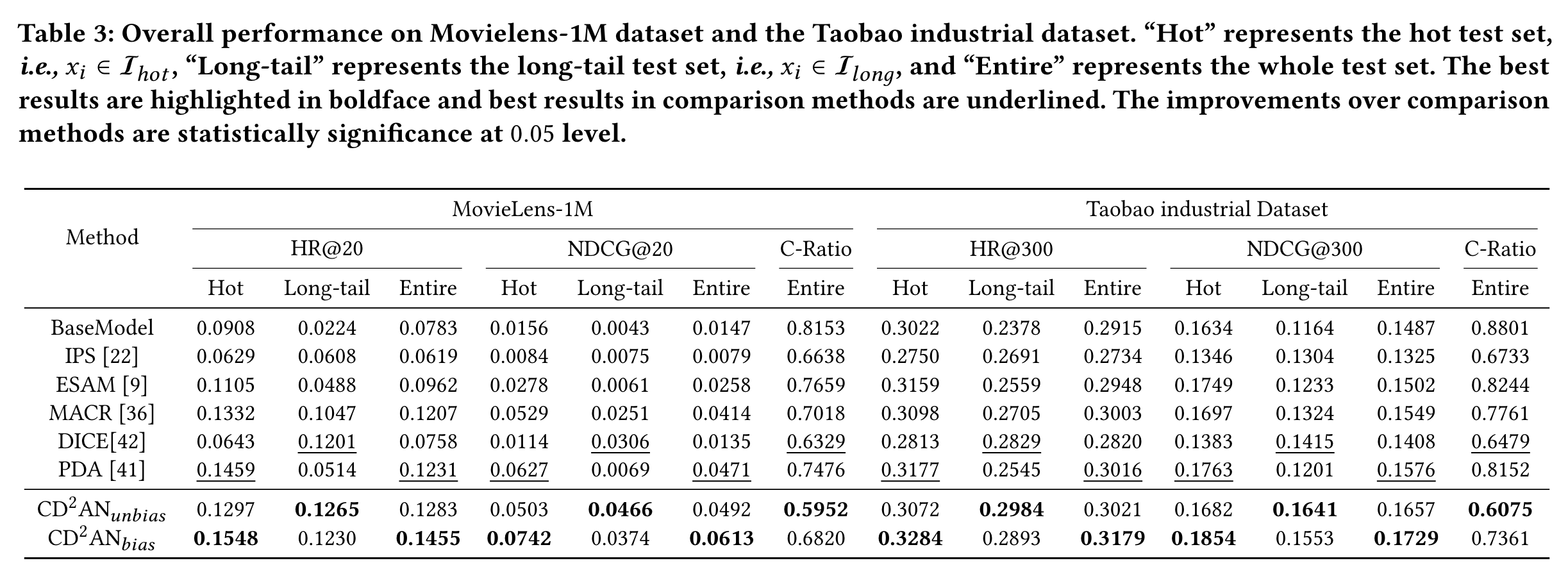
DIHN
(2022)
In this paper, we present a new recommendation problem, TriggerInduced Recommendation (TIR), where users’ instant interest can be explicitly induced with a trigger item and follow-up related target items are recommended accordingly.
In TIR scenarios, users’ instant interest can be explicitly induced with a trigger item.
- Challenge 1: Users’ instant interest induced from a trigger item are inherently noisy,
- Challenge 2: Users always show multiple interests from their historical behaviors.
We propose a novel recommendation method named Deep Interest Highlight Network (DIHN) for Click-Through Rate (CTR) prediction in TIR scenarios.
It has three main components including
- User Intent Network (UIN), which responds to generate a precise probability score to predict user’s intent on the trigger item;
- Fusion Embedding Module (FEM), which adaptively fuses trigger item and target item embeddings based on the prediction from UIN;
- Hybrid Interest Extracting Module (HIEM), which can effectively highlight users’ instant interest from their behaviors based on the result of FEM.
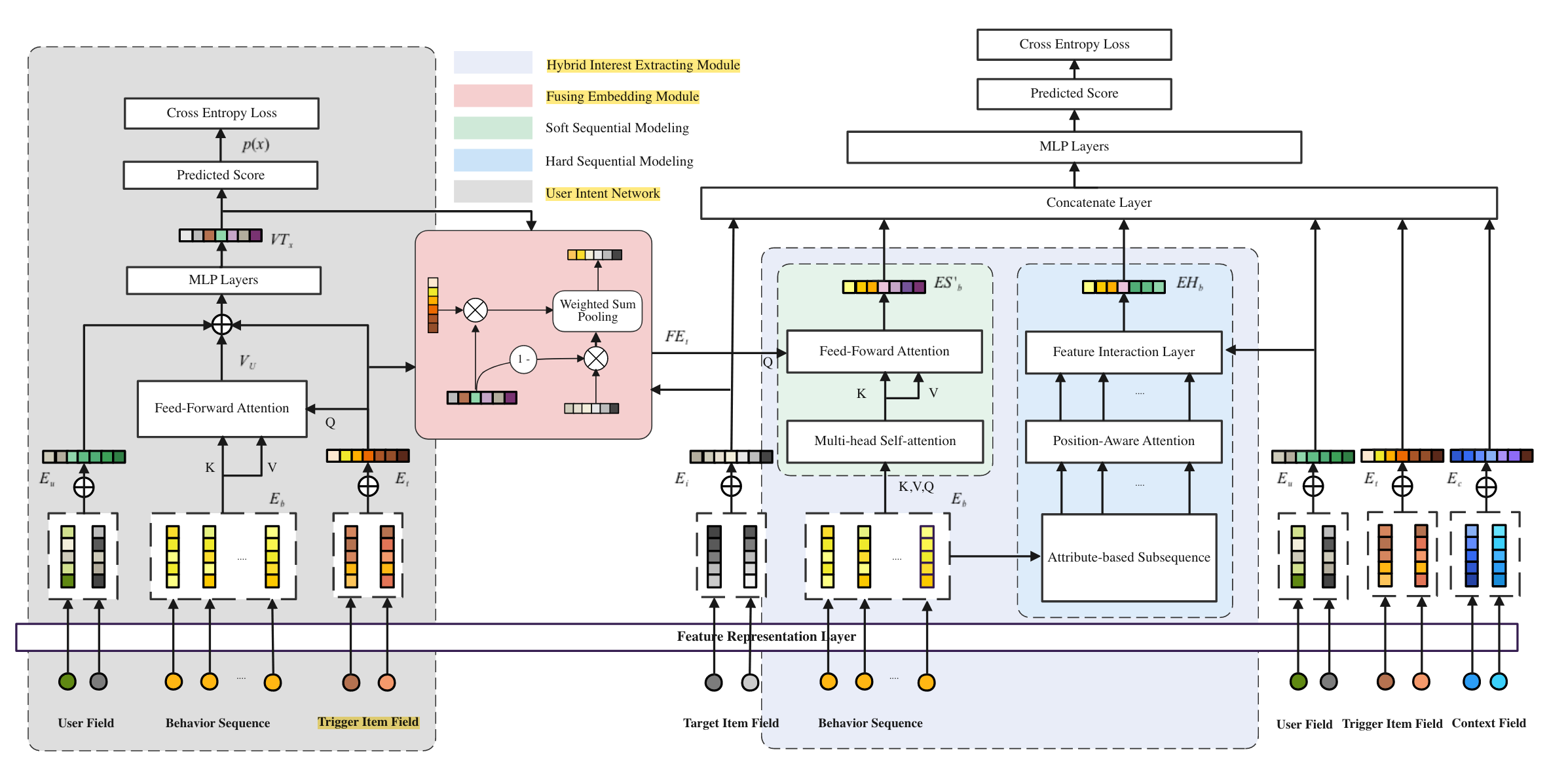
User Intent Network
Referring to the UIN module in Fig.2, where we utilize three categories of features, 𝑖.𝑒, User Profile, User Behaviors, Trigger to estimate the probability.
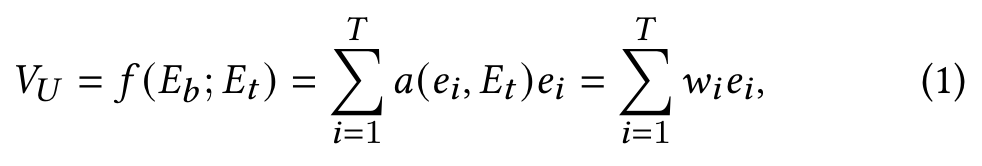
𝑦 ∈ {0, 1} is the ground truth label representing whether users clicking the trigger item or not.
Fusion Embedding Module
A suitable users’ behavior modelling solution could be adaptively fuse the trigger item with target item.
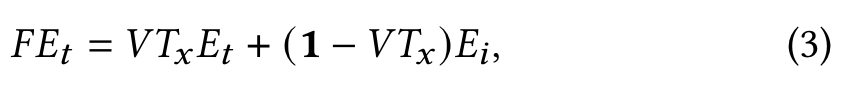
Hybrid Interest Extracting Module
Hard Sequential Modelling
Following the hard-search mode from SIM [13], we propose the Hard Sequential Modelling (HSM), indicating that only behaviors with the same attribute (𝑒.𝑔., category, destination) as the trigger item.
Soft Sequential Modelling
Therefore, from another modelling perspective, we proposed the Soft Sequential Modelling (SSM), which adaptively calculates the representation vector of users’ behaviors with respect to the fusing result from FEM.
Performance
SEMI
(2021)
Existing micro-video recommendation methods only focus on users’ browsing behaviors on micro-videos, but ignore their purchasing intentions in the ecommerce environment.
In this work, we propose to leverage the product-related user behavior data for micro-video recommendation.
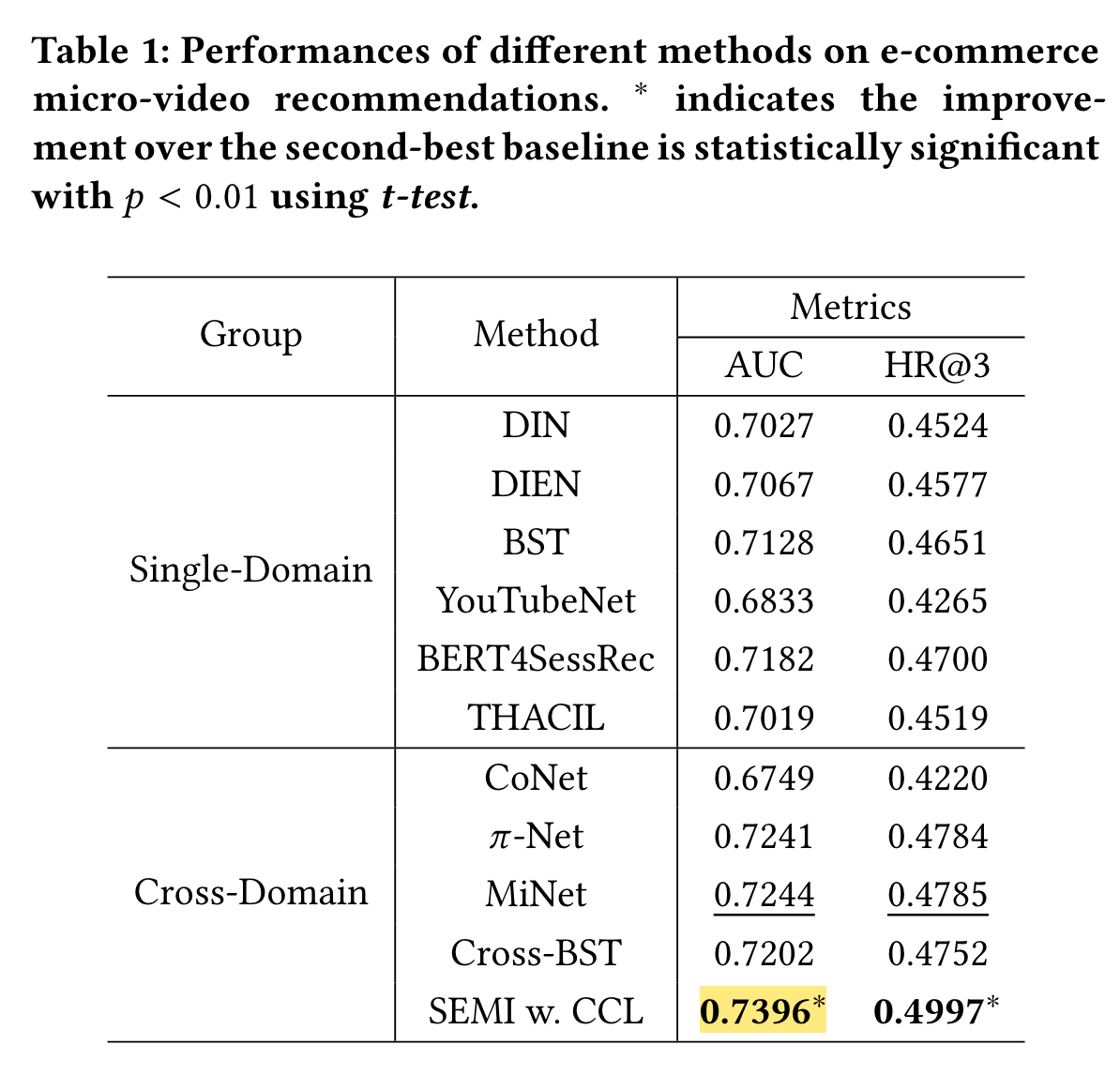
We propose a novel cross-domain recommendation method, named SEquential Multi-modal Information transfer network (SEMI).
To better bridge the behavior pattern gap between micro-video domain and product domain, we further propose a Cross-domain Contrastive Learning (CCL) algorithm to pre-train encoders to describe sequential user behaviors.
Basic Components
Feature Extractor
We adopt UniVL [25] to fuse the multi-modal information of microvideos. Specifically, we utilize micro-video titles and frames as inputs and pre-train the UniVL model using about 100 million ecommerce micro-videos. The pre-training tasks of UniVL include masked language modeling, masked frame modeling, video-text alignment, and tag classifications.
Similarly, we have the semantic representation for each product 𝑝, which is extracted by the pre-trained UNITER model [9].
Multi-Head Attention Block
…
Multi-Modal Sequence Encoder
As the multi-head attention mechanism is not aware of the sequence order information, we use timestamp embedding.
Cross-Domain Contrastive Learning
We propose a Cross-domain Contrastive Learning (CCL) algorithm to pre-train the micro-video and product multi-modal sequence encoders.
The objective of CCL is to encourage the representations of a micro-video sequence and a product sequence to be similar, if they come from the same session of an active user.
Sequential Multi-Modal Information Transfer Network
This is challenging because users’ behaviors in micro-video domain are more sparse than their behaviors in the product domain.
We feed [𝑉 𝑖𝑛𝑡𝑟𝑎, 𝑃𝑖𝑛𝑡𝑟𝑎] into an additional multi-head attention block to capture the inter-domain dependencies, where [·] denotes concatenation.
We utilize another multi-head attention blocks over the target micro-video and {𝑉 𝑖𝑛𝑡𝑒𝑟 , 𝑃𝑖𝑛𝑡𝑒𝑟 }.
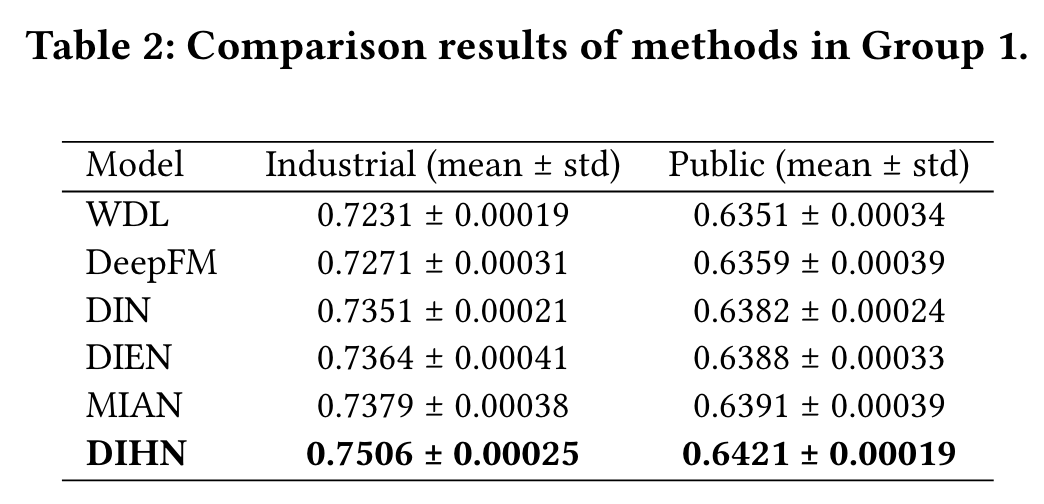
Performance
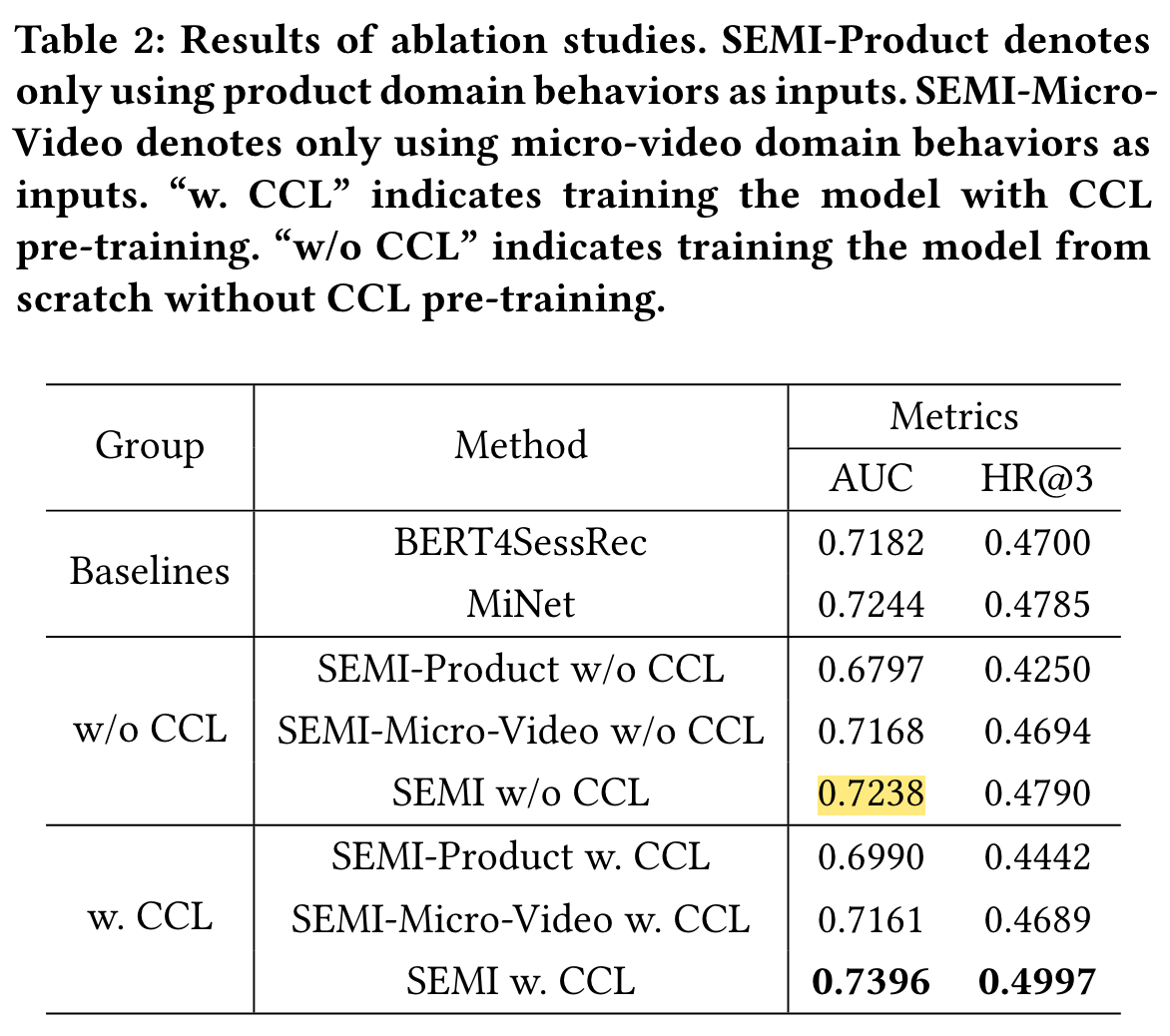
Ablation Studies
IEOE
(2021)
DSSM
(2013)
In this study we strive to develop a series of new latent semantic models with a deep structure that project queries and documents into a common low-dimensional space where the relevance of a document given a query is readily computed as the distance between them.
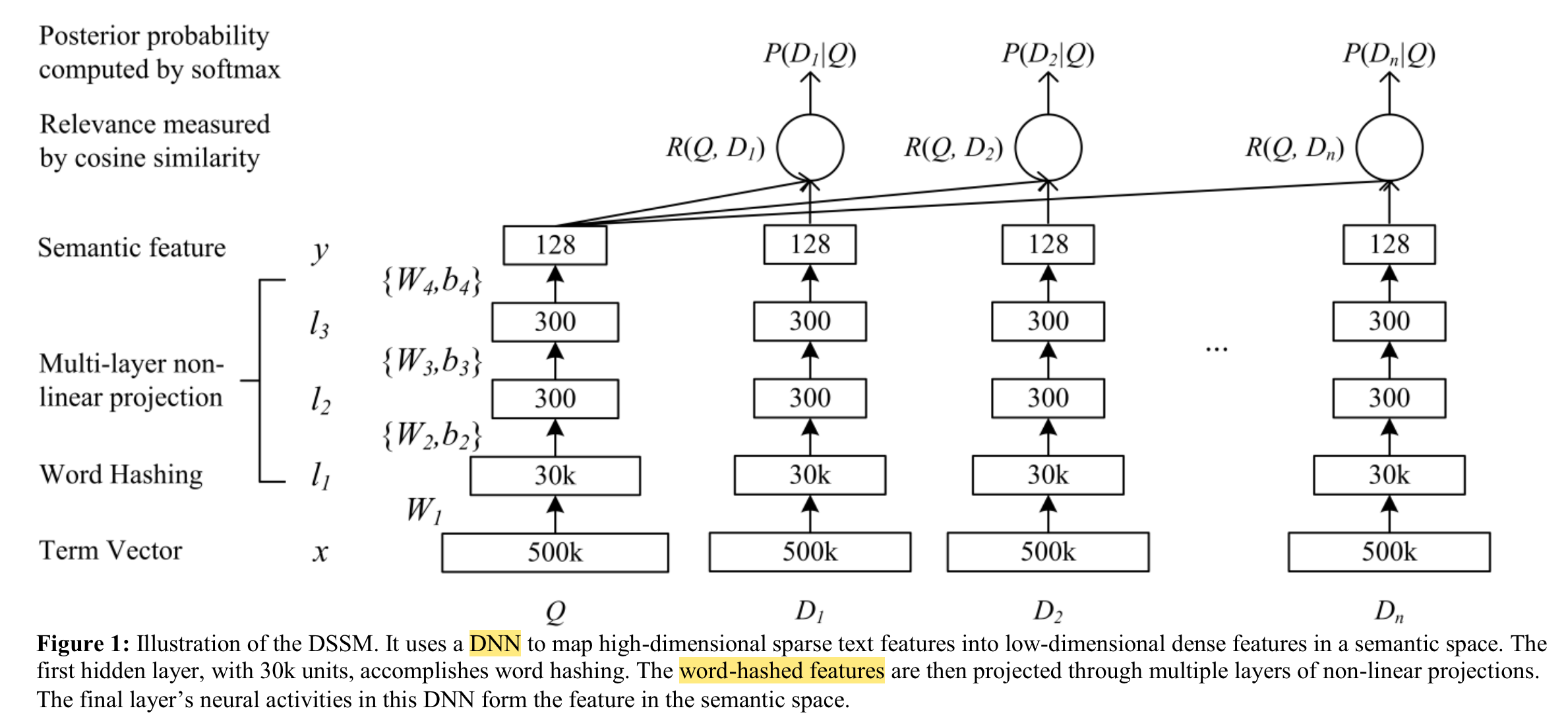
The semantic relevance score between a query and a document is then measured as:
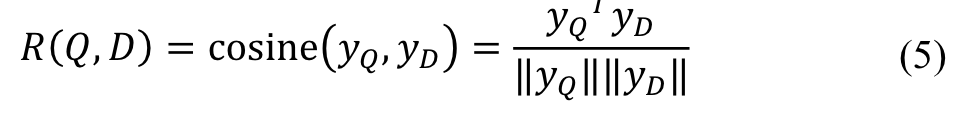
We compute the posterior probability of a document given a query from the semantic relevance score between them through a softmax function:
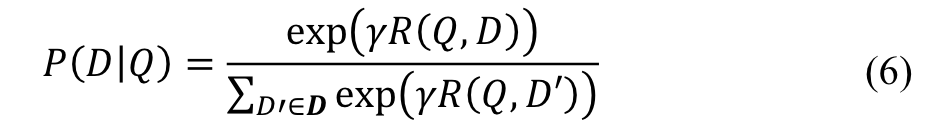
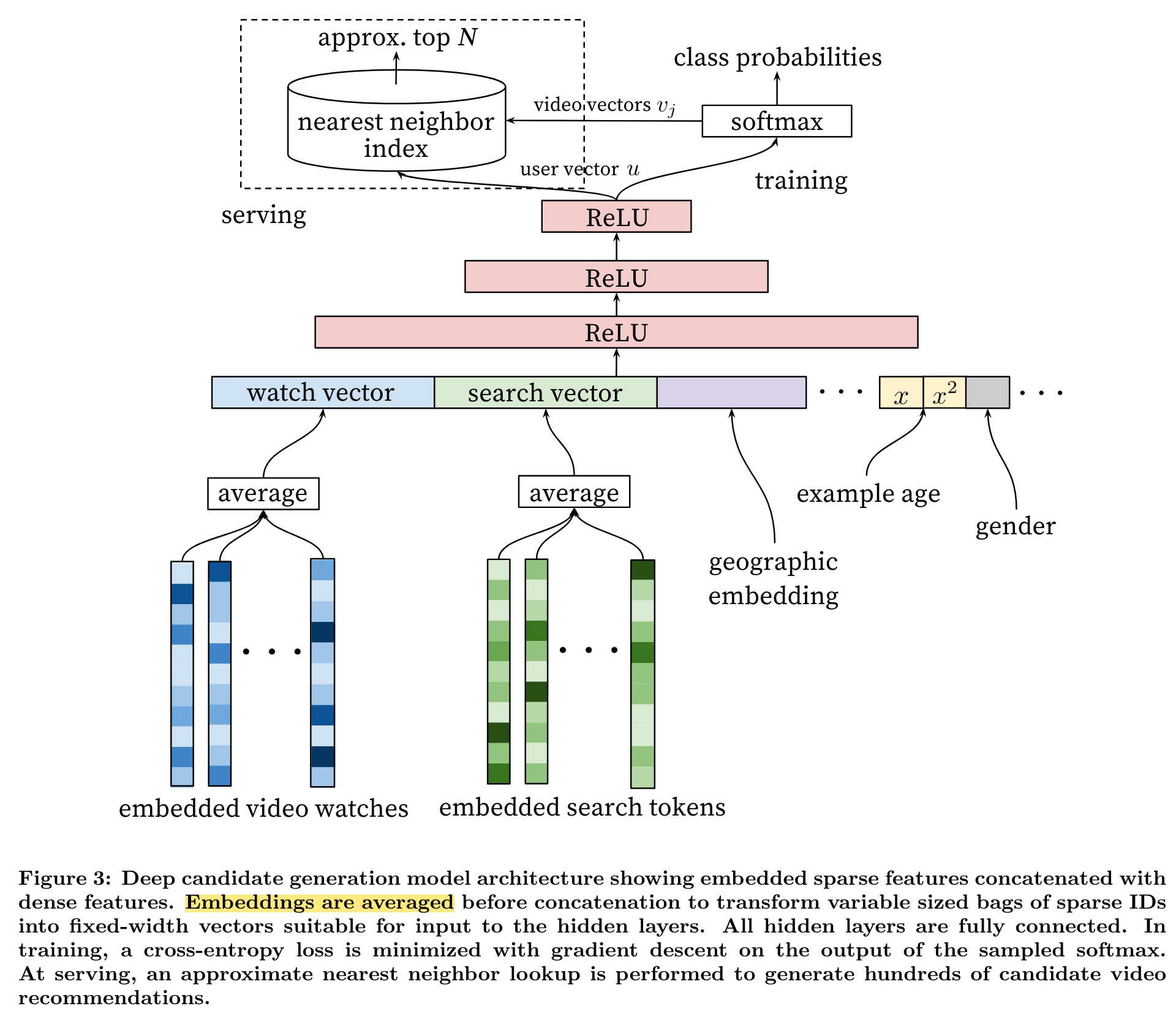
YouTubeNet
(2016)
In this paper, we describe the system at a high level and focus on the dramatic performance improvements brought by deep learning.
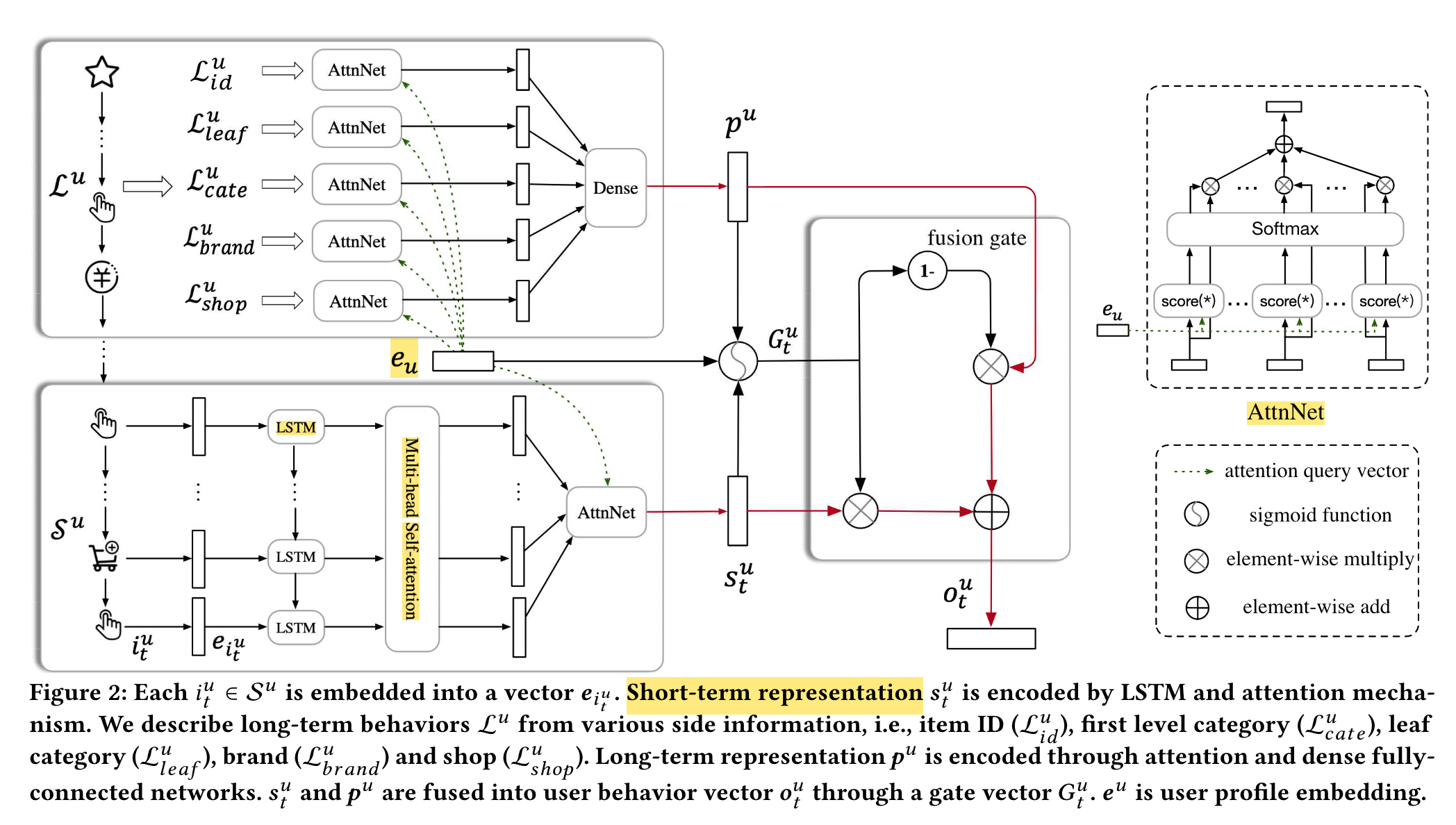
SDM
(2019)
In this paper, we propose a new sequential deep matching (SDM) model to capture users’ dynamic preferences by combining short-term sessions and long-term behaviors.
We tackle the following two inherent problems in realworld applications: (1) there could exist multiple interest tendencies in one session. (2) long-term preferences may not be effectively fused with current session interests.
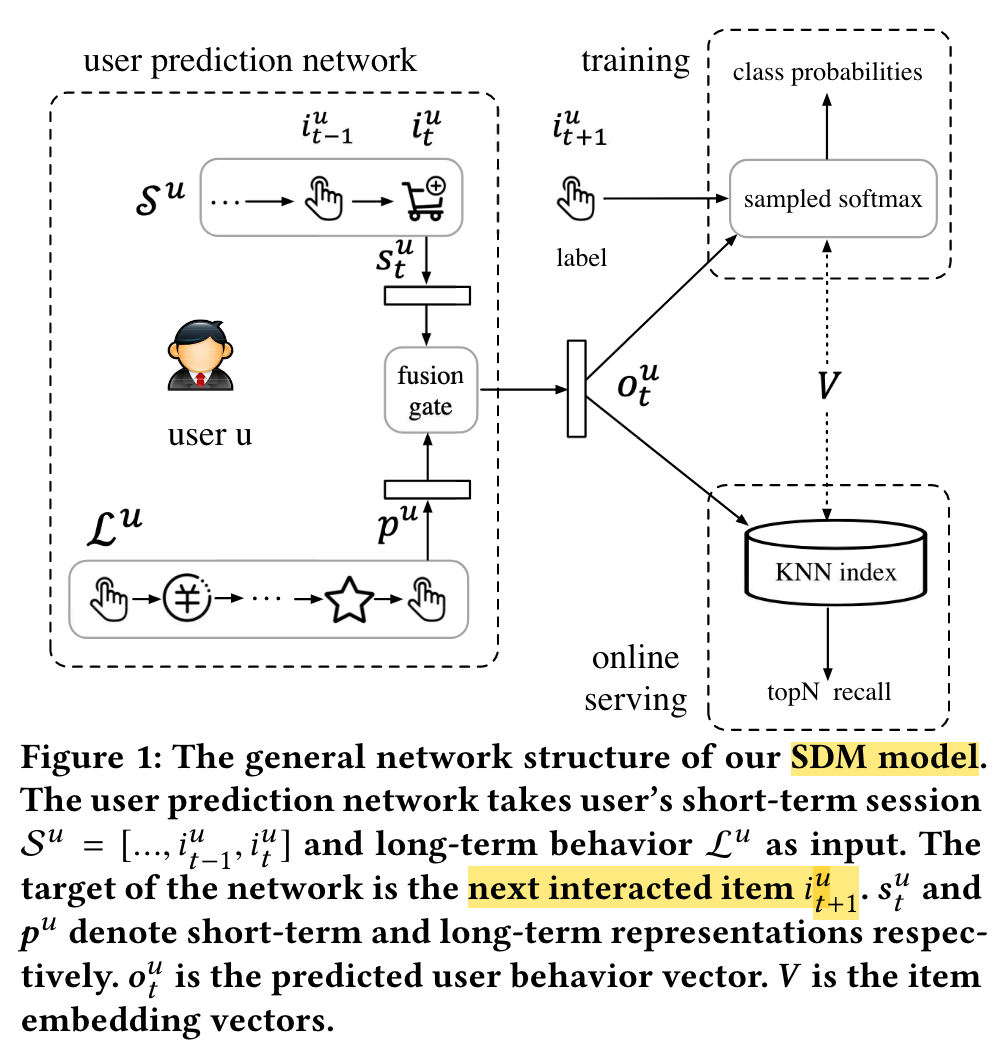
We propose to encode behavior sequences with two corresponding components: multi-head self-attention module to capture multiple types of interests and long-short term gated fusion module to incorporate long-term preferences.
MIND
(2019)
ComiRec
(2020)