
From the Edge to the Cloud: Model Serving in ML.NET
In this paper, they:
- give an overview of current state of the art practices for surfacing ML pipelines predictions into applications
- highlight the limitations of using containers to operationalize models for application consumption.
Model Serving: An Overview
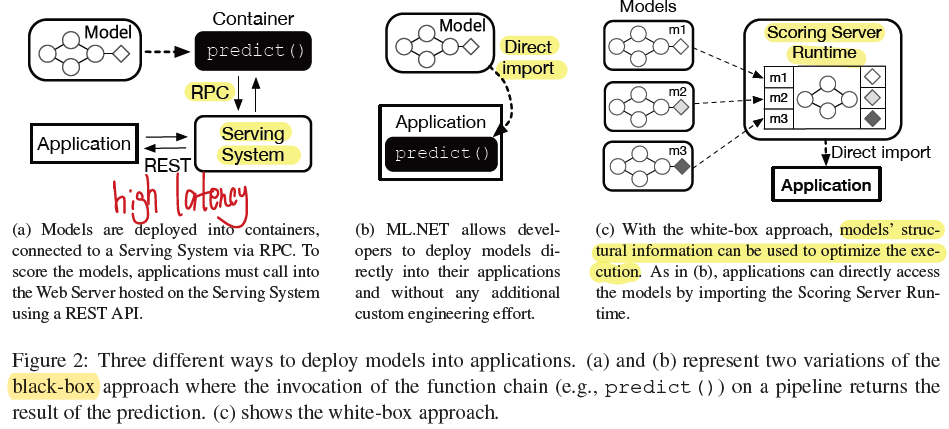
Deploying Models into Containers
The first option, depicted in Figure 2(a) is to ship models into containers (e.g., Docker [4]) wired with proper Remote Procedure Calls(RPCs) to a Web Server. With this approach, predictions have to go through the network and be rendered on the cloud: low latency or edge scenarios are therefore out of scope.
Pros:
- decoupling models from serving system development.
- eases the implementation of mechanisms and policies for fault tolerance and scalability.
- hardware acceleration can be exploited when available.
Cons:
- each container comes with its own runtime and set of processes, thus introducing memory overheads that can possibly be higher than the actual model size.
- the RPC layer and REST API introduce network communication costs.
- only a restricted set of optimizations are available, no knowledge of the internals of the pipelines.
Importing Models Directly into Applications
The second option (Figure 2(b) is to integrate the model logic directly into the application(ML.NET: the model is a dynamic library the application can link). This approach is suitable for the cloud as well as for edge devices and it unlocks low latency scenarios.
Pros:
- removes the overhead of managing containers and implementing RPC functionalities to communicate with the Serving System.
Cons:
- sub-optimal from a performance perspective, DAGs with high chance of overlapping structure and similar parameters, but these similarities cannot be recognized nor exploited using a black-box approach.
White Box Model Serving
Models are registered to a Runtime that considers them not as mere executable code but as DAGs of operators.
Pros:
- apply optimizations over the models such as operator reordering to improve latency or operator and sub-graph sharing to improve memory consumption and computation reuse.
End-to-end Optimizations:
- avoid memory allocation on the data path
- avoid creating separate routines per operator when possible
- avoid reflection and JIT compilation at prediction time
Multi-model Optimizations:
- shareable components have to be uniquely stored in memory and reused as much as possible to achieve optimal memory usage
PRETZEL
PRETZEL views models as database queries and employs database techniques to optimize DAGs and to improve end-to-end performance.
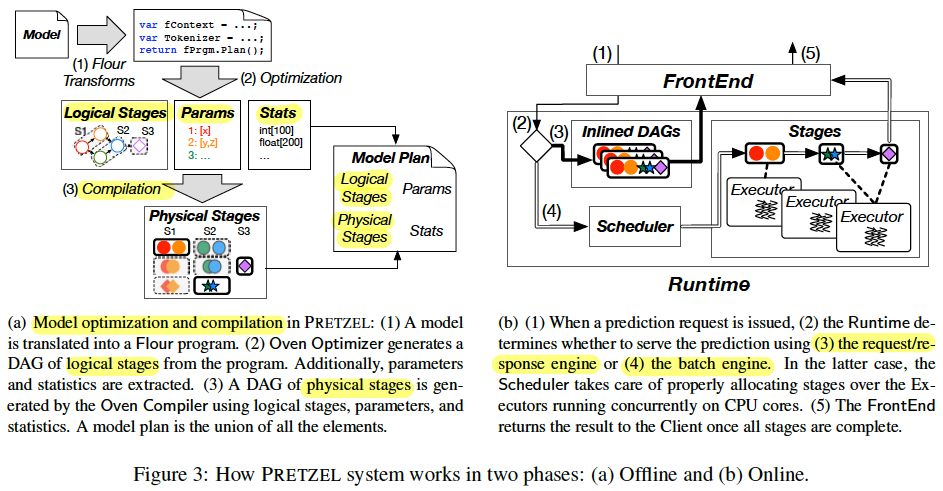
off-line phase:
- pre-trained ML.NET pipelines are translated into Flour transformations.
- Oven optimizer re-arranges and fuses transformations into model plans composed of parameterized logical units called stages.
- Each logical stage is then Ahead-Of-Time(AOT)-compiled into physical computation units.
- Logical and physical stages together with model parameters and training statistics form a model plan.
- Model plans are registered for prediction serving in the Runtime where physical stages and parameters are shared among pipelines with similar model plans.
on-line phase:
- physical stages are parameterized dynamically with the proper values maintained in the ObjectStore.
- The Scheduler is in charge of binding physical stages to shared execution units.
Cloudburst: Stateful Functions-as-a-Service
Today’s popular FaaS platforms only work well for isolated, stateless functions.
The hallmark autoscaling feature of serverless platforms is enabled by an increasingly popular design principle: the disaggregation of storage and compute services.
Unfortunately, today’s FaaS platforms take disaggregation to an extreme.
We are interested in exploring designs that preserve the autoscaling and operational benefits of current offerings(FaaS), while adding performant, cost-efficient, and consistent shared state and communication(Stateful).
Stateful Serverless via logical disaggregation with physical colocation(LDPC):
- deploy resources to diffierent services in close physical proximity.
This paper presents a new Function-as-a-Service platform called Cloudburst. Cloudburst achieves this via a combination of an autoscaling key-value store (providing state sharing and overlay routing) and mutable caches co-located with function executors (providing data locality).
Today’s Serverless Functions:
Function Composition: AWS Lambda imposes a latency overhead of up to 20ms for a single function
invocation.
Direct Communication: point-to-point communication may seem tricky in a system with dynamic membership, distributed hashtables (DHTs) or lightweight key-value stores (KVSs) can provide a lower-latency solution.
Low-Latency Access to Shared Mutable State: worse than shared memory, weak data consistency guarantees.
Stateful Serverless:
distributed storage(KVS server) and local caching(KVS cache).
Coordination-free consistency.
Programming Interface
To enable stateful functions, Cloudburst allows programmers to put and get Python objects via the Anna KVS API.
For repeated execution, Cloudburst allows users to register arbitrary compositions of functions as DAGs.

Architecture

User requests are received by a scheduler, which routes them to function executors. Each scheduler operates independently, and the system relies on a standard stateless cloud load balancer(AWS Elastic Load Balancer).
Function executors run in individual processes that are packed into VMs along with a local cache per VM. The cache on each VM intermediates between the local executors and the remote KVS.
All Cloudburst components are run in individual Docker containers. Cloudburst uses Kubernetes [49] simply to start containers and redeploy them on failure.
Function Executors: Before each invocation, the executor retrieves and deserializes the requested function and transparently resolves all KVS reference function arguments in parallel.
Caches: To ensure that frequently-used data is locally available, every function execution VM has a local cache, which executors contact via IPC.
Function Schedulers: prioritize data locality when scheduling both single functions and DAGs. picks the executor with the most data cached locally.
Monitoring and Resource Management: For each DAG, If the incoming request rate is significantly higher than the request completion rate of the system, the monitoring engine will increase the resources allocated to that DAG function.
Fault Tolerance: If a machine fails while executing a function, the whole DAG is re-executed after a configurable timeout.
Optimizing Prediction Serving on Low-Latency Serverless Dataflow
prediction serving three key properties:
- computationally intensive
- low latency requirements
- compositional, meaning a single request passes through multiple stages.
- (for system) must operate in the presence of bursty and unpredictable workloads.
AWS Sagemaker and Azure ML deploy individual models as separate microservices, However, this approach:
- no visibility into the structure
- how the individual microservices relate to each other, which significantly complicates debugging and limits end-to-end performance optimization.
Pretzel:
requires the developer to rewrite their individual models (i.e., pipeline stages) which is cumbersome and limits model development.
In this paper, (black-box) operators, which are typically models trained by users in their library of choice. A graph of familiar dataflow operators (e.g., map, filter, join) can be used to wrap black-box models.
They present Cloudflow, a dataflow system for prediction serving pipelines. Cloudflow is built on top of Cloudburst.
Architecture and API
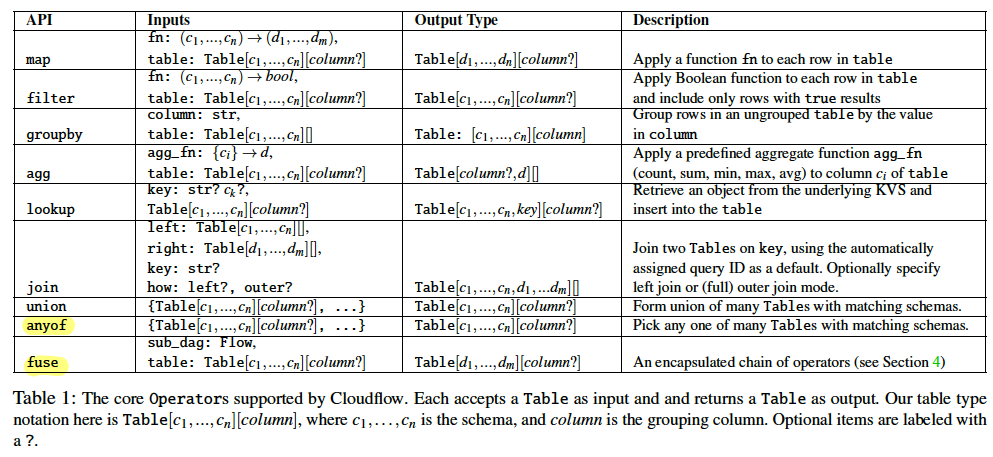
Dataflow API:
anyof passes exactly one of its input tables to the output.
fuse is an internal operator that executes multiple other operators over a Table.

Cloudflow also has an extend method. extend takes in another valid flow as an argument and appends its DAG to the existing flow, creating a dataflow that chains the pair.
Optimizing Dataflows
All the techniques described in this section are automatic optimizations; the user only needs to select which optimizations to enable.
Operator Fusion: compiled into a single Cloudburst function. greedily fuse operators with same resource requirements.
Competitive Execution: reduce the tail latency, redundant parallel replicas of the operator in question and add an anyof to consume the results.
Operator Autoscaling and Placement: Cloudburst natively autoscales function individually. Then we extended the Cloudburst API to allow functions to be annotated with different resource class labels.
Data Locality via Dynamic Dispatch:
- Cloudflow fuses each lookup operator with the operator downstream from it.
- Cloudburst to perform dynamic dispatch of the (fused) operator at a machine that has cached the column value.
Batching: Cloudflow’s API provides a flag for the function arguments to map and filter to declare batch-awareness. Cloudburst dequeues multiple execution requests and executes the entire batch in a single.
Notes
FasS
- low latency
- cost efficieny
- workload burst from 0 to most
- can do training?