
A typical DNN Inference Accelerator stack
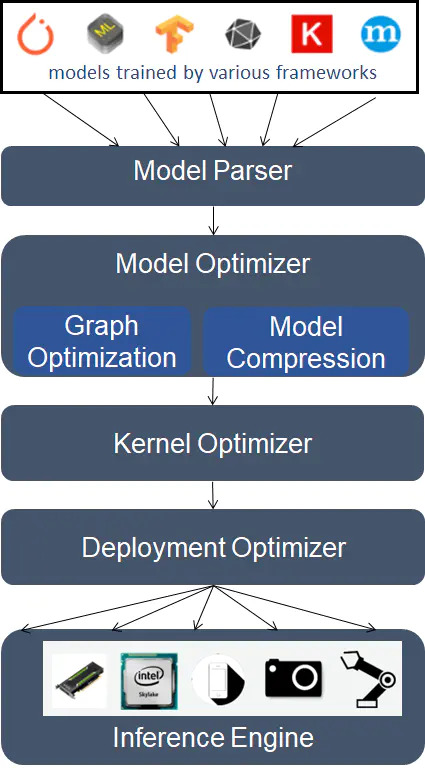
TensorRT for CUDA and OpenVINO for CPU.
NVIDIA TensorRT is an SDK for high-performance deep learning inference. It includes a deep learning inference optimizer and runtime that delivers low latency and high-throughput for deep learning inference applications.
*(ONNX suporrted)
The build phase performs the following optimizations on the layer graph:
- Elimination of layers whose outputs are not used
- Elimination of operations which are equivalent to no-op
- The fusion of convolution, bias and ReLU operations
- Aggregation of operations with sufficiently similar parameters and the same source tensor (for example, the 1x1 convolutions in GoogleNet v5’s inception module)
Merging of concatenation layers by directing layer outputs to the correct eventual destination.
The OpenVINO toolkit is a comprehensive toolkit for quickly developing applications and solutions that emulate human vision. Based on Convolutional Neural Networks (CNNs), the toolkit extends CV workloads across Intel® hardware, maximizing performance.
Steps for Inference Accelerator
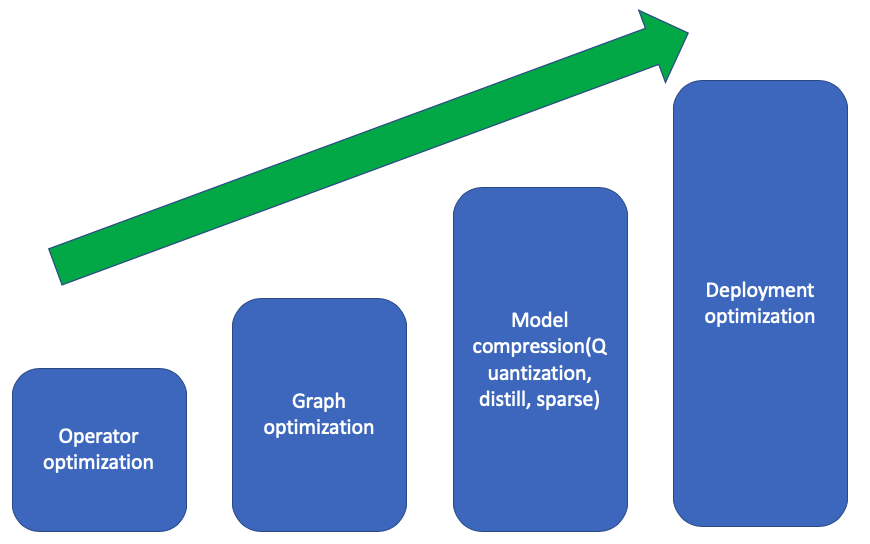
- Operator optimization: lossless optimize a sepcific operator by using expert-designed algorithms.
- Graph optimization: lossless optimize the grph by pruning, fusing or replacing the graph.
- Model compression: lossy optimization by using low precision storage.
- Deploy optimization: resource arrangement and schedule.
Summary
An ADMM Based Framework for AutoML Pipeline Configuration:(hyper-parameter tuning)
- automatically configuring machine learning pipelines(functional modules: preprocessor, transformer, estimator).
- proposes some math notions to represent this problem(pipelines, hyper-parameters, and constraints).
- decomposes the problem into sub-problems.
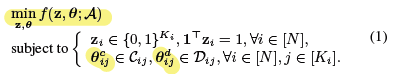

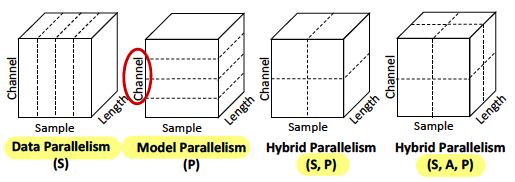
Beyond Data and Model Parallelism for Deep Neural Networks(Graph optimization, Deploy optimization)
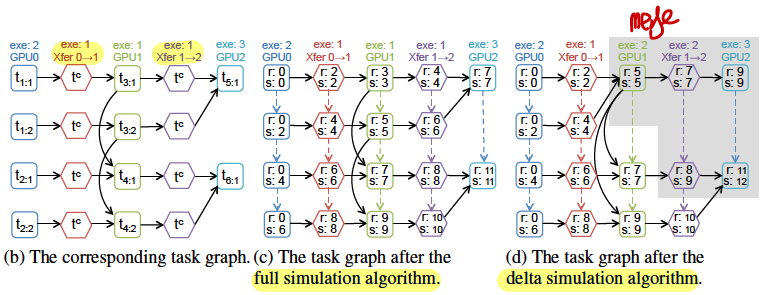
- proposes parallelism dimensions SOAP(Sample, Operation, Attribute, and Parameter dimensions), e.g, Data Parallelism is S, and Model Parallelism is O, P.
- splits a node to Multi-GPUs by SOAP, each as a task, and data transfer is also a task.
- SOAP as a search space, uses MCMC to find efficient task placement.
- uses predicted node excution time as model total execution time.
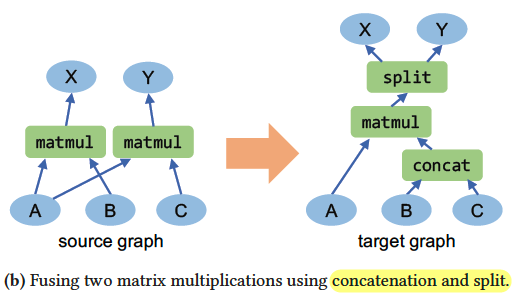
TASO: Optimizing Deep Learning Computation with Automatic Generation of Graph Substitutions(Graph optimization)
- optimizes the graph by using graph substitution.
- DFS algorithm generates all acyclic computation graphs as a substitution if its output is same.
- analyzes the above graph substitution to get operator properties.
- joint optimization with data layout(data stores along which dimension) and graph transformation. TASO measures the execution time and estimates the performance of a graph.

Open problem
- jointly optimize DNN computation at both graph-level and deploy-level(hyper-parameter tuning).
- AutoML Pipeline Configuration with Reinforcement Learning
- (uses the predicted node excution time to compute the model total execution time)
- contribution 1: modules, continuous/integer hyper-parameters, constraints as Reinforcement Learning policy(refer the first paper).
- contribution 2: joint optimization with graph-level and deploy-level(graph optimization on multi-GPUs associate with saveral configuration)(refer the second and third paper).
- contribution 3: ?
- Graph Neural Networks,GNN ?
Draft
- Motivition: accelerate automatically hyperparameter tuning
- Methodology: reinforcement learning
Challenges in hyperparameter search
Costly objective function evaluations
Randomness
Complex search spaces
Related Work
- Reinforcement Learning, optimize device placement for one model, search space, which device the operator should be placed.